Our resources
Our data experts are happy to share their knowledge with the data community. You'll find the articles they've written on this page. These should help you to leverage the potential of your data. Would you like to know more? Please don't hesitate to reach out.



Blog: Notes from PyGrunn 2025: The View from the Stage (and the Audience)
Earlier this year, I had the pleasure of attending and speaking at the Python conference in Groningen, known as PyGrunn.

Blog: Real-time analysis Part 3: Apache Kylin in detail
Part 1 of this series highlighted three distinguishable real-time databases: Apache Druid, Apache Kylin, and Apache Pinot.
Blog: Real-time analysis Part 3: Apache Kylin in detail
Part 1 of this series highlighted three distinguishable real-time databases: Apache Druid, Apache Kylin, and Apache Pinot.

Blog: Is Your Data Still Stafe?
In recent years, cloud adoption has skyrocketed across Dutch companies. From startups to multinationals, organizations rely on the cloud to store, process, and analyze their data. However, a significa…

Blog: Short-term wins, long-term risks - The AI coding dilemma
Since the launch of GitHub's Co-Pilot in 2021, AI-assisted programming has come a long way, evolving from basic line completion to LLM-powered pair programming and architecture reasoning.

Blog: Frameworks for serving machine learning models on Kubernetes
Having worked in the ML field for several years now, I keep seeing the same problems when it comes to professionalising ML workloads.
Blog: Frameworks for serving machine learning models on Kubernetes
Having worked in the ML field for several years now, I keep seeing the same problems when it comes to professionalising ML workloads.

Project-case: CIR & BDR: Partnering to Document Human Rights Abuses with Open Source Data
In today’s connected world, human rights organizations must adapt quickly to manage vast amounts of online open source material.

Blog: Hosting Our Holy Handbook: A Journey in Serverless Simplicity
Here at BigData Republic, we're a small group of data experts. In a small company with distributed ownership and responsibility of processes, they can easily go undocumented or be lost. In order to do…

Blog: Enterprise Patterns in Go: Lessons Learned Through Oldschool Data Platforming
My role for the last many months has been contributing to a project which manages various data services for Scholt Energy here in the Netherlands.
Blog: Enterprise Patterns in Go: Lessons Learned Through Oldschool Data Platforming
My role for the last many months has been contributing to a project which manages various data services for Scholt Energy here in the Netherlands.

Blog: Real-time analysis Part 2: A Closer Look at Apache Druid
In Part 1, we embarked on a journey through the landscape of real-time analytics databases. Now, let's dive deeper into what I find most fascinating about Apache Druid. Whether you're still exploring…
Blog: Decoding Time Series: The Role of Transformers in Forecasting
The success of transformers for different modalities such as natural language, images and video has sparked an exciting research question over the last couple of years: would a transformer-based appro.

Blog: Building Safer AI Chatbots
As Large Language Models (LLMs) increasingly power customer-facing chatbots, ensuring their safety and reliability becomes crucial.
Blog: Building Safer AI Chatbots
As Large Language Models (LLMs) increasingly power customer-facing chatbots, ensuring their safety and reliability becomes crucial.

Blog: Embracing Uncertainty with Conformal Prediction
Data science, at its core, is all about answering questions. What time should I leave for work to avoid traffic? What will the weather be like tomorrow? What's the best price to list my second hand bi…



Blog: Exploring the Uncharted Territories of Math in Data Science
Data science isn't just about crunching numbers or mastering the common areas like statistics and linear algebra.

Blog: Tackling Tradition: The Integration of Artificial Intelligence in Rugby
Recently, Google Deepmind announced TacticAI, an AI assistant for soccer tactics developed in collaboration with Liverpool FC.

Blog: Storage Engines: How Data is Stored
How do modern data stores actually store their data? What are the fundamental data structures used? This blog post covers a few popular data structures and techniques used by data stores nowadays.
Blog: Storage Engines: How Data is Stored
How do modern data stores actually store their data? What are the fundamental data structures used? This blog post covers a few popular data structures and techniques used by data stores nowadays.

Blog: Three Tips to Become a Better Tech Lead
Switching into a lead role is exciting, but can also be a little overwhelming. As a junior or medior your main responsibility is to delivery your own work in good condition, but as a lead you are in c…

Project-case: Harnessing AI for Rail Safety and Efficiency
At BigData Republic, we leverage cutting-edge technology to address complex, real-world problems. Our collaboration with ProRail is a testament to this commitment. The focus of our project there has b…

Project-case: Unleashing the Power of Data: Eneco's Energy Predictions Get a 10% Boost
We worked with Eneco to improve prediction of long term energy use of its clients. We were able to show a 10% improvement compared to current methods and integrate the machine learning predictions int…
Project-case: Unleashing the Power of Data: Eneco's Energy Predictions Get a 10% Boost
We worked with Eneco to improve prediction of long term energy use of its clients. We were able to show a 10% improvement compared to current methods and integrate the machine learning predictions int…

Blog: Data-Driven strategies
In today’s tech landscape, giants like Google and Amazon have showcased the immense potential of data-driven businesses, reaping substantial profits through well-crafted strategies with a focus on sca.

Project-case: Enhancing Soil Insight With Efficient PDF Data Extraction
Give us a task and we start digging! With Stantec we took a jab at their PDF extraction system, and helped them enhance their flagship product, the Soil Risk Map (SRM).

Project-case: Preventing third party incidents with a data-driven tool
Prorail is a Dutch government organization responsible for managing and maintaining the Dutch railway network, which spans 7,000 kilometers.
Project-case: Preventing third party incidents with a data-driven tool
Prorail is a Dutch government organization responsible for managing and maintaining the Dutch railway network, which spans 7,000 kilometers.

Blog: Essentials of an MLOps platform Part 3: Services
An MLOps platform is a collaborative working environment for machine learning engineers that should facilitate iterative experimentation and model deployment.


Blog: Effective Cron Job Monitoring
In our modern world, automation is crucial for the seamless operation of all applications and systems.

Blog: Embracing the Unknown: Lessons from Chaos Theory for Data Scientists
Sometimes during a data science project, you discover that it’s really hard to improve your metric. You try many things: complex models, adding more data, hyperparameter tuning, feature engineering, f…

Blog: Exploring the Dutch AI Ecosystem with Michel Meulpolder
In this edition of The Dutch AI Ecosystem, I had the privilege of interviewing Michel Meulpolder, Managing Partner at BigData Republic.
Blog: Exploring the Dutch AI Ecosystem with Michel Meulpolder
In this edition of The Dutch AI Ecosystem, I had the privilege of interviewing Michel Meulpolder, Managing Partner at BigData Republic.

Blog: The future of data science and what it means for you
The timing is perfect for anyone wanting to do data science in practice right now. Data science is rapidly becoming a commodity. The newly available tools such as AutoML and ChatGPT make it much easie…

Blog: Conflict-Free Pull Requests using dbt Core Custom Schemas
Using dbt Core over dbt Cloud can offer flexibility in use and understanding because of its open-source nature.

Blog: Looking back in time with DBT Snapshots
Every data professional knows that source data is seldom ready for use without some form of preprocessing.
Blog: Looking back in time with DBT Snapshots
Every data professional knows that source data is seldom ready for use without some form of preprocessing.

Blog: How to enforce good Pull Requests on Github
You have worked hard on a new feature or on a bug, and it is time to open a pull request to notify your team members that the feature or fix that you worked on, is ready.

Project-case: "Powering" the Clean Energy Transition with AI at Greener
Greener Power Solutions, the new promising player in the clean energy transition, built a fun group of people to work with.

Blog: Essentials of an MLOps platform Part 2: Infrastructure
Machine learning has become an essential tool for businesses to optimize and automate processes. The term MLOps has already been around for some time now, but that does not mean that it is easy to imp…
Blog: Essentials of an MLOps platform Part 2: Infrastructure
Machine learning has become an essential tool for businesses to optimize and automate processes. The term MLOps has already been around for some time now, but that does not mean that it is easy to imp…

Blog: The essentials of an MLOps platform Part 1: Architecture
When building Machine Learning products, an important aspect is getting the foundation right. You'll need a scalable and solid architecture where these products can be easily deployed and maintained.…

Blog: Detecting Data Drift with Machine Learning
Data changes over time. This is often unpredictable and unannounced. These changes cause a model based on old data to be inconsistent with new data. The performance of the model degrades and you need…

Blog: Should the energy crisis affect the developer agenda?
Everyone is talking about gas prices increasing, inflation, and the global effects of the current energy crisis.
Blog: Should the energy crisis affect the developer agenda?
Everyone is talking about gas prices increasing, inflation, and the global effects of the current energy crisis.

Blog: How to use Slim CI with dbt Core
Dbt is a great tool for data transformations. The paid version, called dbt Cloud, offers Slim CI.

Project-case: Developing and Advanced Best-Next-Action Orchestrator | The case of T-Mobile
Do you remember the last time you were frustrated by a company that just does not know how to communicate properly? Most of us have at least one or two stories in this regard.

Blog: Explainable AI: Understanding the Decisions of a Convolutional Neural Network
How can we define the quality of a convolutional neural network (CNN)? A model’s performance at a given task is often measured by some (simple) predefined metrics.
Blog: Explainable AI: Understanding the Decisions of a Convolutional Neural Network
How can we define the quality of a convolutional neural network (CNN)? A model’s performance at a given task is often measured by some (simple) predefined metrics.

Blog: Testing Strategies for incomplete functionality
When working with code that is not fully functional yet, standard testing approaches in which inputs and expected outputs are defined, might not be sufficient.

Blog: How to build and host beautiful web-based Python apps using Streamlit
Python library Streamlit has been gaining fame as an incredibly easy to use framework for building interactive Python apps since its first release in 2019.

Project-case: Building a vacancy recommender system | The case of Randstad
tldr; Randstad built a vacancy recommender system to match the right candidate to the right job. BigData Republic helped Randstad to tackle two challenges: reciprocity and timely recommendations. The…
Project-case: Building a vacancy recommender system | The case of Randstad
tldr; Randstad built a vacancy recommender system to match the right candidate to the right job. BigData Republic helped Randstad to tackle two challenges: reciprocity and timely recommendations. The…

Blog: Why Data Scientists should write Unit Tests for their code
Within the software engineering industry most developers will be familiar with unit testing. A unit test aims to check whether a part of your code operates in the intended way.

Blog: Building a data platform: gotchas and best practices
Over the course of many different projects, we have built data platforms on every major cloud provider.

Blog: Helping the customer: a start to NBA platforms
You’ve heard talk of Next-Best-Action (NBA) platforms and how great they are at improving customer engagement, like the airline that achieved an 800% uplift in satisfaction and a 60% reduction in chur.
Blog: Helping the customer: a start to NBA platforms
You’ve heard talk of Next-Best-Action (NBA) platforms and how great they are at improving customer engagement, like the airline that achieved an 800% uplift in satisfaction and a 60% reduction in chur.

Blog: Advantages of Serverless Services for Servitization Teams
Imagine: you are working for a company that produces tires. For many years now, your company has been collecting sensor data from the previously sold tires. Now the time has come to extract value from…

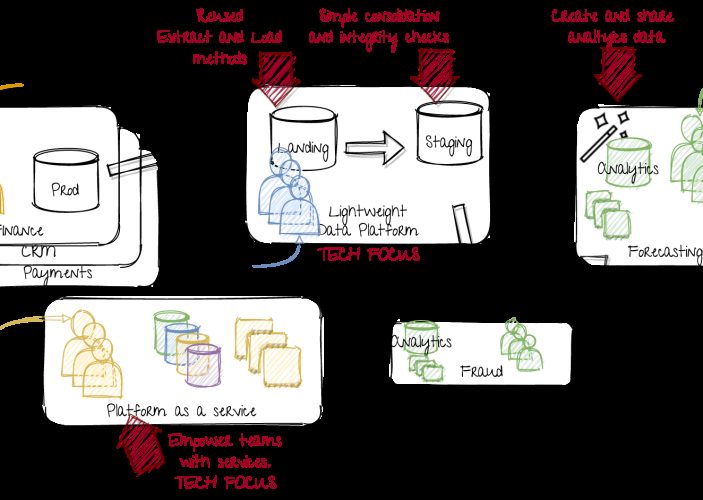
Blog: Two steps towards a modern data platform
When building Data Science products, an important aspect is getting your data available and ready to use.
Blog: Two steps towards a modern data platform
When building Data Science products, an important aspect is getting your data available and ready to use.



Blog: Staying in control of your IAM model
tldr; staying in control of your IAM model is hard, especially when it evolves over time. That is why we built and open sourced Mia. It helps you visualize, explore and query your AWS IAM and Postgres…
Blog: Staying in control of your IAM model
tldr; staying in control of your IAM model is hard, especially when it evolves over time. That is why we built and open sourced Mia. It helps you visualize, explore and query your AWS IAM and Postgres…

Blog: From DevOps to MLOps
DevOps has become an accepted practice in software engineering teams. We see a similar trend starting in the data science and data engineering domain, named MLOps. This blog post explores both and sho…

Blog: Understanding inverse propensity weighting
Today I’d like to explain the underlying concepts of Inverse Propensity Weighting (IPW). As a Machine Learning Engineer, it’s important to know how models and algorithms work. This allows you to deter…

Blog: Data science is boring
TL;DR
Data scientists should become MLOps Engineer or an Analytics Translator.
Blog: Data science is boring
TL;DR
Data scientists should become MLOps Engineer or an Analytics Translator.


Blog: Automating Software Versioning on Kubernetes
The Kubernetes community is growing rapidly with many cool new open source projects popping up all the time.

Blog: Architecting a workable, yet secure data exploration environment on the Google Cloud Platform
Having worked for multiple major organisations in the Netherlands, there's always this recurring topic: how to give data scientists as much freedom as possible for exploring data, while minimising the.
Blog: Architecting a workable, yet secure data exploration environment on the Google Cloud Platform
Having worked for multiple major organisations in the Netherlands, there's always this recurring topic: how to give data scientists as much freedom as possible for exploring data, while minimising the.

Blog: Kinesis Data Analytics SQL: a cautionary review
You use AWS. You need to perform real-time feature processing all while maintaining state. Could Amazon Kinesis Data Analytics be a solution to your problem? What about concerns such as testability, c…

Podcast: Scaling ML capabilities in large organizations
A podcast on machine learning platforms: what are their features, which complexities arise around them and how to bring a machine learning model to production.
Blog: Dealing with abrupt market changes in your analysis - a brief tutorial on time series change point detection
The Covid-19 crisis has an extraordinary effect on global economic activity. After this crisis it will remain important to take this period into account when training machine learning models on histor…
Blog: Dealing with abrupt market changes in your analysis - a brief tutorial on time series change point detection
The Covid-19 crisis has an extraordinary effect on global economic activity. After this crisis it will remain important to take this period into account when training machine learning models on histor…

Blog: Writing functional DSLs for business domains
In functional programming, a domain specific language (DSL) is a set of functions that can be composed to solve a specific problem.

Blog: Improving the security of Data Science containers
No one wants to be the person who exposed sensitive information through their container and caused a hefty GDPR fine, right? What then should data scientists do to improve the security of their contai.

Blog: How to grow as a data science professional - introducing the Skill Stack
Professionals need to grow and develop their skills to advance in their career. That’s not different for a data scientist. There are various skills, all contributing to your impact on the project. Dev…
Blog: How to grow as a data science professional - introducing the Skill Stack
Professionals need to grow and develop their skills to advance in their career. That’s not different for a data scientist. There are various skills, all contributing to your impact on the project. Dev…

Blog: Machine learning models on AWS with the Rendezvous architecture
tl;dr Testing and updating machine learning models can be done safely and systematically using the Rendezvous architecture.

Blog: AWS Lambda: Comparing Golang and Python
Serverless functions are great for lightweight cloud architecture and rapid provisioning. However, sometimes serverless introduces additional complexity to the deployment process. I compare Python and…

Blog: Hosting workshops on AWS using ECS, EC2 and Terraform
During workshops, I often see participants wrestle with software installation before they can get started.
Blog: Hosting workshops on AWS using ECS, EC2 and Terraform
During workshops, I often see participants wrestle with software installation before they can get started.

Blog: Preventing churn like a bandit - with uplift modeling, causal inference, and Thompson sampling
Blog: Preventing churn like a bandit - with uplift modeling, causal inference, and Thompson sampling
The real goal is to prevent churn, not to predict churn. Thus, we predict the effect of treatments. The transformed outcome technique is helpful. It changes the labels in the dataset such that our mod…

Blog: A review of Netflix's Metaflow
tl;dr Metaflow is a framework that alleviates several infrastructure-related pains data scientists experience in their projects.

Blog: Keeping your ML model in shape with Kafka, Airflow and MLFlow
Fitting and serving your machine learning model is one thing, but what about keeping it in shape over time?
Blog: Keeping your ML model in shape with Kafka, Airflow and MLFlow
Fitting and serving your machine learning model is one thing, but what about keeping it in shape over time?

Blog: On machine learning team composition
Getting machine learning off the ground requires many skills and capabilities. Some of these skills are related, some are not. For example, knowledge of math and knowing when to use which machine lear…

Blog: For effective treatment of churn, don't predict churn
In the business to consumer market, there are two strategies to grow market share: gaining new customers, and retaining existing customers.

Blog: Advanced Pandas: Optimize speed and memory
Nowadays the Python data analysis library Pandas is widely used across the world. It started mostly as a data exploration and experimentation tool but is slowly transitioning to be used in a productio…
Blog: Advanced Pandas: Optimize speed and memory
Nowadays the Python data analysis library Pandas is widely used across the world. It started mostly as a data exploration and experimentation tool but is slowly transitioning to be used in a productio…

Blog: You don't have enough Analytics Translators, here's why that's a problem
I often get asked the question ‘Why do AI projects fail?’ As a data science consultant, I’ve seen a variety of organizations struggle to make AI work for them.

Blog: From predictive to prescriptive analytics - the benefit of causal diagrams
Suppose you work at as a data scientist at a dating site. Recently more and more customers are closing their accounts (a.k.a. churning). You want to understand which customers are likely to close thei…

Blog: Using Bayesian Optimization to reduce the time spent on hyperparameter tuning
Common hyperparameter tuning techniques such as GridSearch and Random Search roam the full space of available parameter values in an isolated way without paying attention to past results.
Blog: Using Bayesian Optimization to reduce the time spent on hyperparameter tuning
Common hyperparameter tuning techniques such as GridSearch and Random Search roam the full space of available parameter values in an isolated way without paying attention to past results.

Blog: Beating the Bookies with Machine Learning
“The dealer always wins” is a typical saying in gambling. It reflects the fact that in most games of chance the house (e.g. the casino or the bookmaker) has a statistical advantage. In other words, as…

Blog: Cost comparison of deep learning hardware: Google TPUv2 vs Nvidia Tesla V100
Google offered us a chance to test their new TPUv2 devices for free on Google Cloud as part of the TensorFlow Research Cloud program.

Blog: Integrating Pandas and scikit-learn with Pipelines
Scikit-learn and Pandas are both great tools for explorative data science. Both require a bit of practice to get the hang of. The phrase “Hey Alex, how do I achieve the following in Pandas?”, is often…
Blog: Integrating Pandas and scikit-learn with Pipelines
Scikit-learn and Pandas are both great tools for explorative data science. Both require a bit of practice to get the hang of. The phrase “Hey Alex, how do I achieve the following in Pandas?”, is often…

Blog: Machine learning for predictive maintenance: where to start?
Think about all the machines you use during a year, all of them, from a toaster every morning to an airplane every summer holiday.