Real-time analysis Part 3: Apache Kylin in detail

Dima Baranetskyi
Part 1 of this series highlighted three distinguishable real-time databases: Apache Druid, Apache Kylin, and Apache Pinot. In Part 2, we dove deep into the fascinating innards of Apache Druid, and now it's Kylin's turn to be under our magnifying glass. If you're still window shopping for your perfect real-time analytics solution, it might be better to start with Part 1 first; otherwise, buckle up as we explore Apache Kylin's unique approach to real-time analysis as a leading OLAP cube specialist!
Is Apache Kylin the right tool for my use case?
“To know the road ahead, ask those coming back.”Chinese Proverb
Your data analysis band isn’t just familiar with OLAP cubes — they embrace them with open arms. The business side constantly asks for real-time BI reporting, and predefined analytics sits proudly in your toolkit arsenal. Whether by historical accident or deliberate choice, your data landscape is thoroughly Hadoop-based, and real-time data analysis touches numerous facets of your operation. Does this sound like your world? Then Apache Kylin might just slide perfectly into your data toolbox.

But what will Apache Kylin not do for you?
- Apache Kylin is not a replacement for traditional OLTP solutions. Trying to use Kylin for systems requiring ACID transactions, row-level updates, or point lookups would be like using a telescope to read a book. Its immutable cube structure fundamentally clashes with applications requiring frequent write operations or transaction processing.
- Apache Kylin is excessive for small-to-medium scale reporting. If your data volumes hover below 10GB with straightforward reporting needs, deploying Kylin would be overkill. A standard data warehouse would elegantly suffice without the Hadoop ecosystem overhead.
- Apache Kylin falls flat for text search and natural language processing. Kylin’s architecture shines with numeric aggregations and dimensional analysis, but stumbles with text processing or search functionality. For use cases centred on full-text search, sentiment analysis, or other text-focused operations, specialised tools would serve you far better than attempting to squeeze these workflows into Kylin’s OLAP cube paradigm.
Before choosing Apache Kylin, carefully consider these critical trade-offs:
- Significant infrastructure requirements. Kylin’s deep Hadoop ecosystem dependency introduces substantial overhead in terms of infrastructure, maintenance, and operational complexity. The considerable hardware resources needed for building and storing OLAP cubes make Kylin potentially prohibitive for organizations without a dedicated big data infrastructure. This resource overhead becomes particularly challenging when dealing with high cardinality dimensions that cause a cube explosion.
- Limited flexibility for exploratory analytics. Kylin’s pre-built cube approach demands that dimensions and metrics be defined upfront, making it ill-suited for exploratory analytics or environments where query patterns evolve frequently. The cube build process creates an unavoidable time gap between data ingestion and query availability, hampering true data exploration workflows where future questions remain unknown.
- Batch-oriented architecture with streaming limitations. Despite advancements in its streaming capabilities, Kylin remains fundamentally a batch-oriented system at its core. For use cases requiring genuinely sub-second query responses on freshly ingested data, Kylin’s architectural approach creates inherent latency challenges that purpose-built real-time systems were specifically designed to overcome.
These are some of the key points about Apache Kylin’s dependencies and architectural trade-offs. The system’s reliance on the Hadoop ecosystem provides powerful distributed computing capabilities but introduces significant operational complexity. While Kylin supports real-time streaming, its foundation remains batch-oriented, potentially limiting performance in low-latency scenarios. Despite these considerations, Kylin remains a powerful solution for organizations with existing Hadoop infrastructure looking to implement high-performance OLAP analytics at scale.
If you’re still engaged, keep reading as we explore more about Kylin’s architecture, capabilities, and use cases in depth.
What kind of software is Apache Kylin?
“The jade stone is useless before it is processed; a man is good for nothing until he is educated.”Chinese Proverb
In its fundamental nature, Apache Kylin operates as a Java-based solution. This seemingly straightforward characterisation has profound implications — it requires substantial Java knowledge, particularly regarding JVM behaviour, garbage collection, and memory management. Kylin’s foundation rests firmly on the Hadoop ecosystem’s shoulders, making Hadoop expertise not just beneficial but often essential for those seeking to harness Kylin’s capabilities fully.

Examining Kylin’s technological underpinnings reveals several critical dependencies that define its functionality:
- Apache Zookeeper (helped by Apache Curator) — functioning as the nervous system that coordinates Kylin’s distributed elements, handling everything from leader election to process discovery. This grants Kylin remarkable resilience but introduces a layer of complexity that administrators must master.
- Apache Calcite — serving as the brain behind Kylin’s SQL implementations. While Calcite handles the parsing, optimisation, and planning stages, Kylin has extensively customised it to excel specifically with OLAP-style analytical workloads.
- Apache Spark acts as the computational muscle powering OLAP cube creation. Kylin employs a specially modified version that has been fine-tuned for the specific demands of multidimensional cube processing at scale.
- Apache Gluten serves as a potential performance accelerator by offloading JVM-based SQL execution to native engines like Velox or ClickHouse. This middle layer transforms Spark’s physical plans into native execution, offering significant speedups for Kylin’s Spark-based computations without abandoning its powerful OLAP cube paradigm.
- Apache Hive and Hive-HCatalog operate as the data librarians that manage metadata and table access patterns. They play a crucial role in Kylin’s ability to convert raw Hadoop/Hive data into optimised analytical structures.
- RoaringBitmap functions as a specialised indexing technology that enables rapid set operations. This component proves vital for Kylin’s bitmap indexing performance and features Kylin-specific optimisations.
- Ehcache, Redis, Lettuce — forming the memory acceleration layer that dramatically improves query response times. This distributed caching framework is key to Kylin’s capacity to deliver rapid responses even with complex analytical queries.
A thoughtful analysis of these dependencies reveals telling characteristics about Kylin’s true identity:
- Kylin is built on Hadoop, requiring specialized operational skills. Organizations without Hadoop face steep setup and management challenges.
- It includes custom dependencies beyond standard open-source releases. These can complicate upgrades and future compatibility efforts.
- Kylin’s architecture spans multiple components with distinct responsibilities. Managing them demands careful coordination and resource planning.
Despite its complex dependencies and Hadoop ecosystem requirements, Kylin transforms the challenge of big data analytics into a solvable problem. For teams willing to navigate its Java and Hadoop underpinnings, Kylin’s sophisticated OLAP engine delivers analytical capabilities that turn mountains of data into actionable insights at speeds that can feel almost magical.
Native ingestion capabilities
“Swift as the wind, quiet as the forest, fierce as fire, immovable as a mountain.”Sun Tzu, The Art of War
Regarding ingestion, Apache Kylin relies on four main connectors: Apache Hive, Apache Kafka, Apache Iceberg, and a universal JDBC connector. While batch processing with Hive is Kylin’s traditional strength, let’s focus on its streaming capabilities that enable real-time analytics.
Apache Kylin’s Real-Time feature supports querying streaming data with reduced latency from ingestion to analysis. The primary streaming pipeline centres around Kafka integration, with the Streaming Message Parser handling the transformation of incoming data streams into formats Kylin can efficiently process and index.
The implementation follows a structured workflow: first connecting to Kafka data sources, then configuring the streaming tables, and finally making the data available for real-time querying. We can reasonably assume that standardization of the topic’s schema might be crucial here. Kylin, allows combining dimensional data from batch sources with streaming fact tables, creating a unified analytics environment for hybrid data processing needs.
Technically, Kylin maintains the cube-based approach for streaming data, creating segments that can be queried while they’re still being built. This architecture allows Kylin to leverage its OLAP strengths while accommodating the continuous nature of streaming data. The platform handles both the immediate processing of incoming streams and the eventual merging of segments for optimal query performance.
For organisations already using Kylin for batch analytics, the streaming capabilities provide a natural extension without requiring a separate system. This has the potential to reduce data inconsistency issues and management complexity.
Understanding Apache Kylin's architecture
“When nothing is done, nothing is left undone.”Laozi, Tao Te Ching, Chapter 48
Apache Kylin’s architecture centres around the OLAP cube paradigm, with all state information stored in a relational database. This design enables Kylin to function either as a cluster of specialised nodes or as a single-node deployment for simpler use cases.
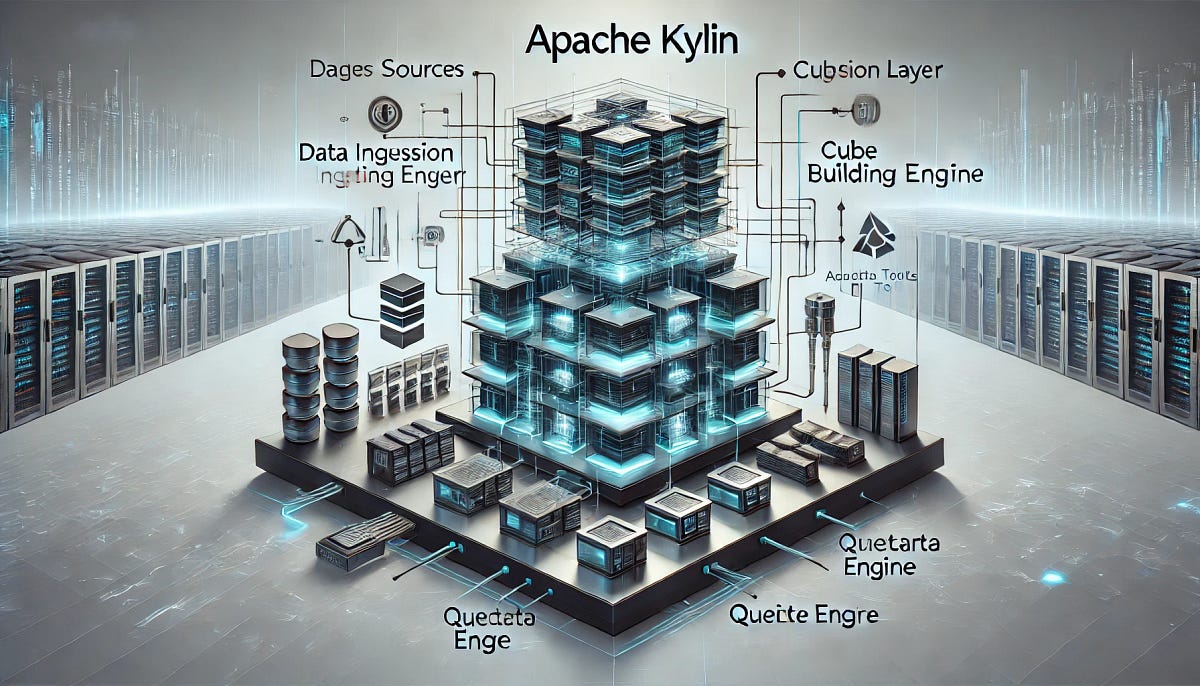
Kylin separates responsibilities across specialised node types:
- Query Nodes handle user queries and submit building jobs without executing them
- Job Nodes execute the resource-intensive cube-building jobs and metadata operations
- All Nodes perform both query and job functions, which is the default in single-node deployments
The core components work together to deliver Kylin’s OLAP capabilities:
- Metadata Database (PostgreSQL or MySQL) stores cube definitions, job information, and system configuration
- Streaming Component processes real-time data from Kafka, transforming incoming streams into queryable formats
- Job Engine manages and executes the cube build processes, orchestrating the precomputation of aggregations
- Query Engine translates SQL queries into optimized operations against the precomputed cubes
- Service Discovery uses Apache Curator and ZooKeeper to coordinate cluster activities
Kylin’s storage architecture reflects its integration with the Hadoop ecosystem:
- Metadata Storage in RDBMS provides the structural information needed for system operation
- Cube Storage leverages Hadoop to store the precomputed cube segments in a distributed manner
- Source Data Storage connects to batch sources like Hive and streaming sources like Kafka
For high-performance environments, Kylin supports read/write separation across Hadoop clusters, preventing resource contention between build operations and query workloads. This architecture allows Kylin to deliver consistent performance even under mixed analytical workloads.
Both cluster and single-node deployments follow this same architectural approach, with the difference being the distribution of components rather than their fundamental operation.
Deploying Apache Kylin
“The man who moves a mountain begins by carrying away small stones.”Confucius
So you’ve wrapped your head around Kylin’s architecture and now you’re ready to bring this OLAP powerhouse to life! Deployment is where the rubber meets the road — transforming Kylin from an interesting concept into a lightning-fast analytical engine at your fingertips.
Before you dive in, you’ll need to gather your ingredients:
- A working Hadoop environment with the usual suspects: HDFS, YARN, and either MapReduce or Spark
- A metadata database (PostgreSQL preferred, but MySQL works too) to store Kylin’s operational brain
- Java 8+ runtime (because what Java project doesn’t need Java?)
- A dedicated Linux user — giving Kylin its own playground keeps things tidy
- Some properly permissioned HDFS directories for Kylin to store its work
- A reasonable amount of memory — 16GB total with 8GB for Kylin if you’re serious about performance
Kylin is flexible about where it lives, offering several deployment styles:
- Single-node mode for the minimalists or those just starting their Kylin journey
- Cluster mode when you need to scale out and handle serious workloads
- Read/write separation for the performance purists who don’t want their queries competing with cube builds
Cloud aficionados aren’t left out either — Kylin plays nicely with all the major cloud platforms, leveraging their managed Hadoop offerings and database services to minimise infrastructure headaches.
For the “try before you buy” crowd, the Docker image apachekylin/apache-kylin-standalone lets you spin up a self-contained Kylin environment with minimal fuss. It’s great for exploration, though not intended for production workloads.
The Kubernetes landscape is still a bit of frontier territory for Kylin. While it can run in containers, you’ll need to be something of a pioneer to create your own K8s configurations since there’s no official operator or Helm chart yet.
If you’re looking for the white-glove treatment, Kyligence Enterprise offers a commercial, feature-enhanced version of Kylin with full support — think production-ready deployments and enterprise-grade integration across on-prem or cloud.
When plotting your deployment strategy, keep these factors in mind:
- The scale of your data and query needs
- How fast do you need those queries to come back
- Whether downtime gives you nightmares
- How Kylin will fit into your existing data ecosystem
- Whether your team is ready for Hadoop administration adventures
For most real-world scenarios, a cluster deployment strikes the sweet spot between performance and manageability, giving your analysts the speed they crave without keeping your ops team up at night.
Extending Apache Kylin
“The bamboo that bends is stronger than the oak that resists.”Japanese Proverb
Apache Kylin isn’t just a powerful analytical engine — it’s a platform designed for extension and customisation. In a data-driven world, the ability to tailor your analytical tools can make the difference between simply storing data and fully leveraging it.

Kylin’s architecture is built for extensibility, offering several key customization points:
- Custom Parser SDK lets you handle complex Kafka message formats. To create a parser, you set up a Maven project, extend the AbstractDataParser class, implement the parse() method, and register it via the service loader.
- Multi-level Partitioning allows you to partition cubes across multiple dimensions, improving query performance for specific access patterns.
- Model Management enables flexible customisation of data models, including hierarchies, derived measures, and complex joins, without needing custom code.
- Segment Management gives you control over data lifecycle operations, allowing for custom retention policies and partition strategies based on your resource and business needs.
Kylin integrates easily with popular visualisation tools:
- JDBC Driver connects Kylin to Tableau, Power BI, QlikView, MicroStrategy, and other JDBC-compatible tools. Connection follows the format jdbc:kylin://<hostname>:<port>/<project_name> with standard authentication options.
- ODBC Drivers (via third-party adapters) enable access for tools that don’t support JDBC, expanding Kylin’s reach.
Programmatic access is extensive:
- REST API provides endpoints for authentication, project and model management, query execution, and job monitoring.
- Callback API supports asynchronous workflows by sending notifications when jobs complete.
- Custom Parser Jar Management lets you upload custom code through the API, removing the need for direct server access.
- REST API Authentication supports both basic and advanced authentication schemes through HTTP headers, ensuring secure integration.
The combination of these extension points makes Kylin more than an OLAP engine. It becomes a flexible platform that adapts to your data ecosystem, whether you are connecting BI tools, building custom applications, or automating analytical workflows.
Apache Kylin SQL capabilities
“Study the past if you would define the future”Confucius
SQL is the lingua franca of data analysis, and Apache Kylin embraces this standard with robust support for the ANSI SQL 2003 specification. Kylin’s SQL capabilities form the backbone of its analytical prowess:
- Multi-Dimensional Analysis: GROUPING SETS, ROLLUP, CUBE
- Window Functions: ROW_NUMBER(), RANK(), sliding aggregations
- Pushdown Query Engine: routes unsupported cube queries to SparkSQL
- Asynchronous Query Execution: handles large or long-running queries
- Time-Series Analysis: timestamp-based grouping and filtering
- Join Operations: supports complex star and snowflake schemas
- Advanced Functions: mathematical, statistical, string ops

What makes these features shine is their synergy with Kylin’s OLAP architecture. When a query aligns with pre-aggregated cube data, you get lightning-fast responses. If not, SparkSQL handles the heavy lifting without disrupting the user experience.
Kylin also packs smart optimisation under the hood. Segment pruning skips irrelevant data using dimension range metadata. Semantic tricks like converting LEFT JOINs to INNER JOINs boost performance. Even conditional aggregates like SUM(CASE WHEN ...) are pre-computed when possible.
And if you’re juggling multiple models, Kylin’s routing logic picks the best one based on freshness, dimensionality, and complexity — though you can steer it manually with query hints if needed.
In short: Kylin speaks fluent SQL and thinks fast. It balances precision and performance, making it a go-to choice for teams that need analytics speed without ditching the familiar SQL dialect.
“As the water shapes itself to the vessel that contains it, so a wise man adapts himself to circumstances.”Confucius
Apache Kylin’s true value is best demonstrated through its real-world applications.

Several major organizations have transformed their data capabilities with Kylin:
- Transsion leverages Kylin as their metrics store engine, managing thousands of key mobile business metrics.
- Industrial Bank of China (CIB), with its 100+ million cardholders, uses Kylin for credit card data and user portrait analysis.
- TP-Link employs Kylin to analyze massive IoT device operation data, monitoring equipment versions in real-time.
- SF-Tech and ZTO Express, both logistics giants, selected Kylin for financial metrics processing and operational intelligence, powering data cockpits and dashboard analysis.
- Tomato Games built a self-service platform using Kylin, enabling business users to analyze data through familiar tools like Excel for improved targeting and operations.
These are just a handful of examples — for a comprehensive list of organisations leveraging Apache Kylin in production, check out the official Apache Kylin use cases page.
As we conclude our exploration of Kylin, several key insights emerge: Kylin excels with predefined OLAP queries on massive datasets. Its Hadoop integration creates both opportunities and challenges, while its streaming capabilities bridge batch and real-time analytics. Successful implementations require thoughtful cube design and dimension selection, but the diverse real-world applications demonstrate Kylin’s maturity as an enterprise platform.
For organizations with well-defined analytical needs on massive datasets, Kylin offers a compelling solution balancing performance, scalability, and analytical depth.
Stay tuned for the next installment in our real-time analytics series, where we’ll continue exploring powerful solutions for today’s data-driven organizations.