Decoding Time Series: The Role of Transformers in Forecasting

Robbert van Kortenhof
The success of transformers for different modalities such as natural language, images and video has sparked an exciting research question over the last couple of years: would a transformer-based approach also work for other modalities? Among these, the modality of time series has been at the center of many discussions. In trying to answer this question, a surge of papers and forecasting libraries flooded the field, all with their own take on a transformer capable of time series forecasting. Some were very promising, others less so. Now, with the introduction of foundation models for time series and the first extensive benchmarks being published, let's have a look at transformers and their place in the forecasting toolbox.

How transformers work for time series
First, let’s take a moment to originate where the question of transformers’ potential in the context of time series forecasting (TSF) comes from. After the successful application of transformers in the field of natural language, and later images and video, similarities were drawn between the sequence of words and the sequence of numerical values in time series. Transformers were able to capture the complex, interdependent patterns in high-dimensional data that is natural language, making way to the question: what would be so different about time series?
To contextualize the performance of transformers and understand their potential and shortcomings, let’s have a brief look at the key components of a transformer in the context of TSF. If you want to have a more fundamental understanding of how transformers work in general, I strongly recommend this blog post, offering a visual, conceptual introduction to the topic. For this post, we will limit our focus to three concepts: the encoder layer, self-attention modules and the decoder layer.
Encoder layer
Contrary to many other deep learning approaches to TSF, transformers have no repetition mechanism handling the time series sequence in separate timesteps. Instead, transformers are inherently order-agnostic and read the input data as a whole. To still capture sequence information (such as the order of the values), these temporal relationships are encoded into the input data through vectors. These encodings can be statically defined or learned by the encoder layer.
Sequence information that can be encoded include positional encoding (absolute or relative position of every value), timestamp encoding (e.g., per second, minute, hourly or irregular) as well as special timestamps (e.g., holidays and events). A more advanced example would be that of spatio-temporal forecasting, where the model must learn and embed location-specific dependencies.
As a simplified example, the encoder layer considers information such as the positions of the values in the time series sequence, and the encoding would then look as follows:
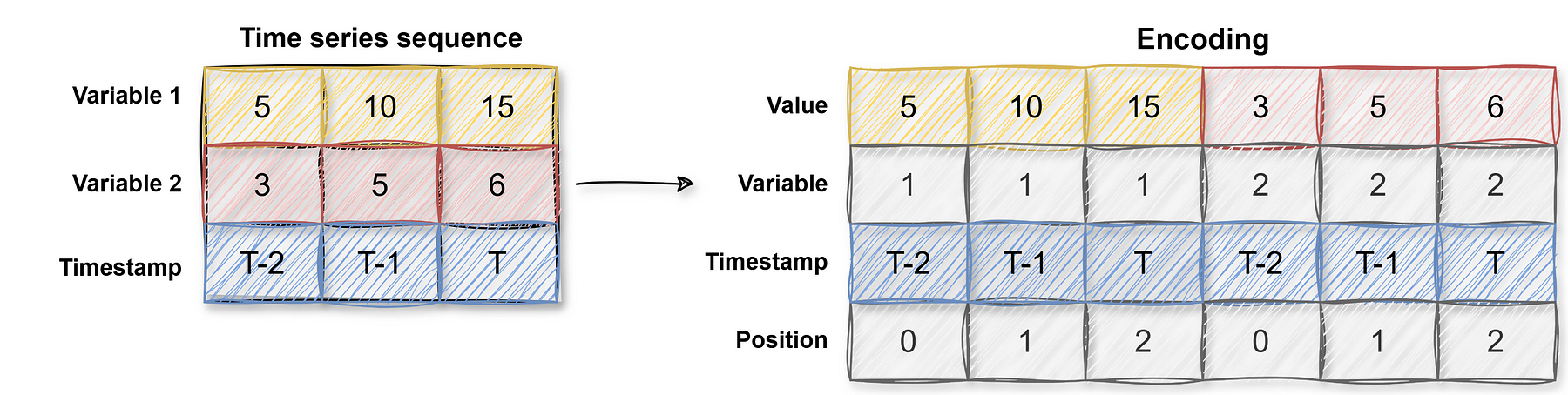
Self attention modules
Another key concept is that of self-attention modules, which are part of the encoder layer. These modules assign attention scores to the data by learning which parts of the sequence are most important. There are generally two types of attention mechanisms.
- Single-head self-attention
Each data point is compared to every other data point to compute attention scores. In the context of TSF, it could for example look for sharp spikes and drops in a sequence, assigning these points a higher attention score. - Multi-head self-attention
The multi-head variant uses multiple perspectives to come to the conclusion what parts of the sequence need a higher attention score. In addition to looking for sharp spikes and drops, it could also consider long-term dependencies such as seasonal patterns or correlations between irregular events. For the original paper on multi-head self-attention, please have a look here.
This process of comparing every data point to every other data point becomes very computationally expensive very quickly and is referred to as the quadratic time complexity problem. A common solution for this problem are self-attention modules with sparse attention: instead of comparing all data points with each other, the modules only consider a subset of the sequence. Examples of this are local attention, in which only the local neighbors of a data point are considered, strided attention, where every k-th data point will be part of the subset and block-sparse attention, in which the sequence is windowed and attention scores are computed within or between specific blocks.
Decoder layer
The decoder layer utilizes the vectors and attention scores to predict the most likely subsequent value(s) in the sequence. This layer typically consists of its own additional self-attention modules and feed-forward layers, generating predictions by leveraging the encoded representation of the time series sequence. This layer could also integrate other network types such as a convolutional neural network.
Bringing it together
By discussing the encoder layer, self-attention modules and decoder layer, we have effectively gone through an encoder-decoder transformer architecture. To draw the comparison once more, in NLP three main configuration are used:
- Encoder-only models: Focused on understanding the input, often used for classification tasks. A prominent example would be BERT.
- Decoder-only models: Predict the next token or sequence, used for generation tasks. An example would be OpenAI’s GPT models.
- Encoder-decoder models: The encoder processes the input sequence into a representation, which the decoder uses to generate the output. In NLP, this approach is used for translation models.
In the context of TSF, the encoder-decoder approach works like a translation model. However, instead of mapping between two natural languages, it maps a time series sequence to predictions of future, unseen time steps.
A diagram bringing these concepts together is shown below, displaying Nixtla’s TimeGPT architecture.
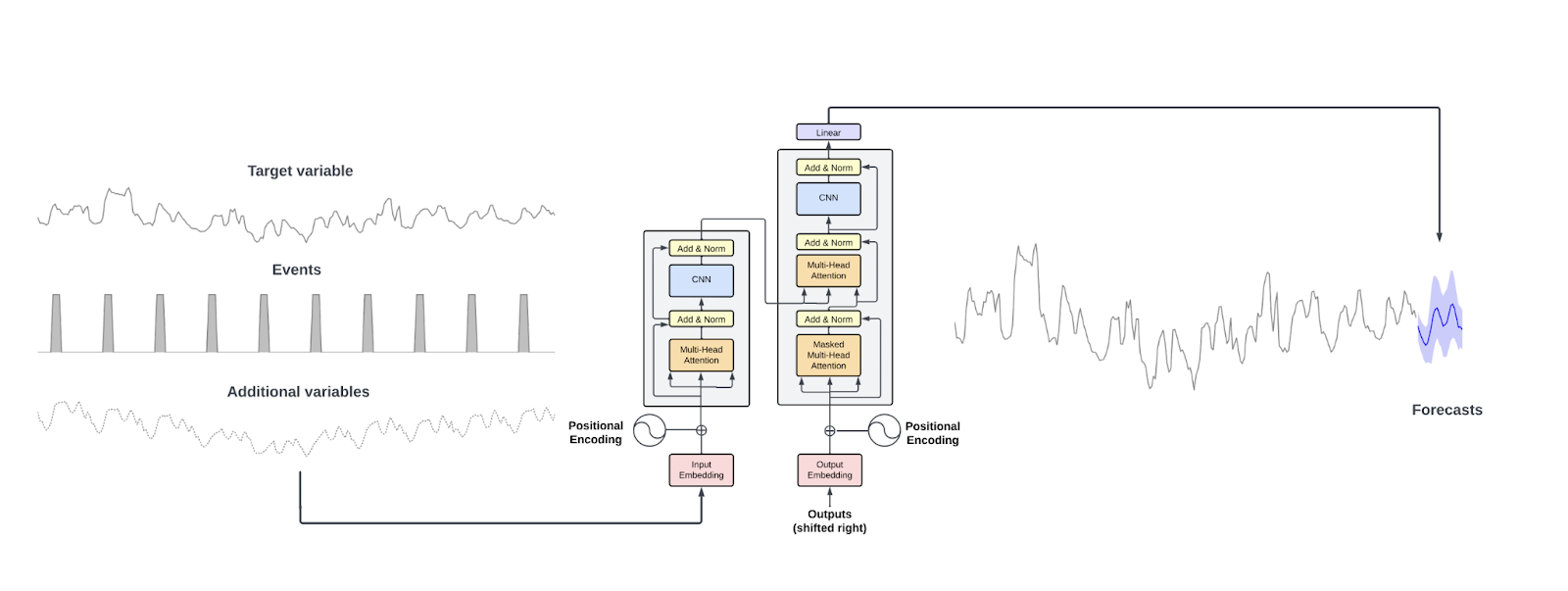
Nixtla's TimeGPT architecture
And how they sometimes don’t work
These ingredients make transformers a potentially powerful option for TSF problems. That being said, it’s not all smooth sailing. For instance, time series sequences are not as semantically rich as natural language, images, or videos. Unlike these domains, time series tend to be continuous-valued, noisier and less intuitively structured, which makes pattern recognition more difficult. Additionally, the meaning of a time series sequence is often highly domain-specific. By comparison, text retains much of its semantics across contexts, whereas time series sequences vary significantly depending on the real-world scenario, making it harder to transfer knowledge across domains.
Furthermore, transformers can still struggle with temporal information loss despite positional encoding due to the permutation-invariant nature of the self-attention mechanisms, resulting in issues with maintaining the necessary temporal relationships. Another challenge has already been mentioned in the form of the scalability limitations of the sequence length. Due to their quadratic computational complexity, training with long sequence lengths can become quite expensive. One more obvious challenge is that to utilize their architecture’s complexity and number of parameters, transformers need a significant amount of training data, which can be hard to come by in TSF. Finally, the interpretability of transformers and their results leave a lot to be desired, though some suggestions are being put forward to deal with this.
Transformer-based foundation models
Despite — or perhaps because of — these points of debate, the number of papers on how transformers should (or shouldn’t) be applied to time series continues to grow. While a full review is beyond the scope of this blogpost, let’s have a look at a new direction that appears to be taking shape within this surge of research. Especially in the first half of 2024, many studies were published on transformer-based foundation models for time series.
Research shows roughly three different approaches to foundation models for time series.
- General-purpose foundation model
This approach involves building a general-purpose foundation model trained on a significant amount of time series data. - Specific-purpose foundation model
Similar to the general purpose approach, except the foundation model is tailored around and trained on data from a specific field. An example could be a foundation model specific to pandemic-related data, sharing characteristics such as seasonality and trends across different viruses. - Leveraging LLMs
In this approach, numeric values in a sequence are converted into words, after which a LLM generates the most likely subsequent values. The LLM output, being words, is then converted back into numeric values.
A feature shared by all three approaches is the capability of “zero-shot” forecasting; forecasting without any further fine-tuning or additional training to a specific use case. This capability builds upon the idea that time series sequences, in their essence, represent a universal language. There are differing opinions on to which extend this holds true (if at all), which supports both specific-purpose and general-purpose foundation models.
The principle behind general purpose foundation models aligns with this notion, suggesting that, regardless of the specific domain, time series sequences capture underlying patterns — such as trends, cycles, and dependencies — that are common to many different processes. By learning these general structures, models can apply their understanding across diverse contexts, making it possible to forecast future values even in unfamiliar situations. From a more practical point of view, in cases where little data is available or rapid results are needed, foundation models, both general and specific-purpose, can forecast right out of the box, offering possibly a beneficial accuracy versus speed trade-off.
Some of the most prominent suggestions for general-purpose foundation models include Amazon’s Chronos, Google’s TimesFM and Nixtla’s TimeGPT. Other foundation models that were released earlier this year are Salesforce’s Moirai, Lag-Llama and MOMENT. Some of these differentiate themselves from the bunch with unique architectures—like TimesFM, which uses a decoder-only transformer—or by offering advanced modeling features such as probabilistic forecasting and custom loss functions. Others provide an Excel plug-in? As for specific-purpose foundation models; IBM and NASA released a foundation model tailored to weather and climate forecasting.
Putting transformers to the test
Fortunately, this wave of papers and models has been met with a healthy dose of skepticism that pointed out the need for transparent benchmarking, including common TSF baselines and models. And while several have now been published, it is to be expected that this will be an ongoing back-and-forth for the foreseeable future — as long as new transformers are being proposed, their initial results will be met with more thorough comparison papers. With time, the foundation models will also start to be included in these reviews more regularly, the majority having only been released in the first half of 2024.
The first, very skeptical benchmark from 2023 indicated a poorer or very similar performance by local transformers when compared to a much simpler combination of linear models referred to as DLinear. Specifically, transformers seem unable to adequately capture the trend and periodicity present in longer time series sequences. Whereas DLinears performance increases when the look-back window is increased in size, the transformers’ performance worsens or remains stable. These results are illustrated below. This benchmark did not remain unanswered and was provided with somewhat of a counter-benchmark, showing that one of the transformers in question (Autoformer) was actually more capable than the suggested combination of linear models.
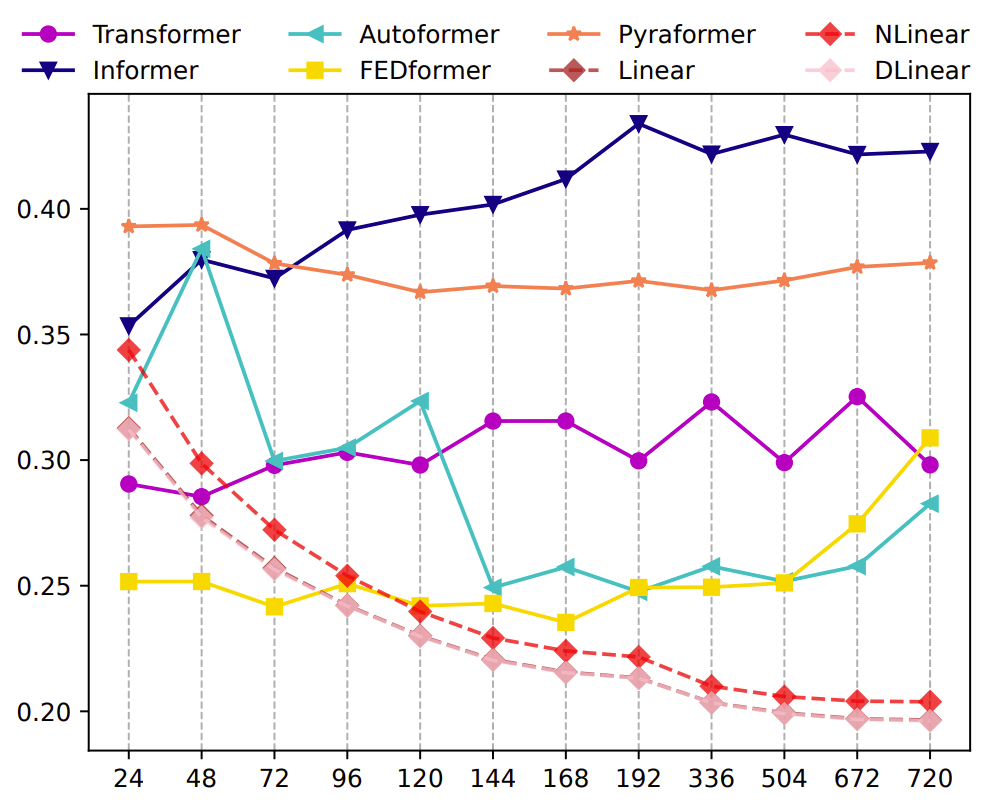
The MSE results (Y-axis) of models with different look-back window sizes (X-axis) of long-term forecasting (T=720) — Zeng, A., Chen, M., Zhang, L., & Xu, Q. (2023). Are Transformers Effective for Time Series Forecasting?. Proceedings of the AAAI Conference on Artificial Intelligence, 37(9), 11121–11128. https://doi.org/10.1609/aaai.v37i9.26317
One other resource that has been very insightful is Nixtla’s transformer experiment collection. Here, multiple foundation models are reviewed and compared to each other in addition to more traditional statistical methods. Instead of solely looking into accuracy metrics, computation time is also considered. In short, similar results are found as several foundation models struggle with outperforming (ensembles of) standard methods while being significantly slower. The developers behind Amazon’s Chronos disagreed with their application of their model and provided a counter-review, sparking an interesting discussion on benchmarking in general.
Nixtla’s latest comparison may indicate a turning point, revealing potential improvements in foundation model performance. Earlier this year, they released an extensive, reproducible benchmark including the most prominent foundation models as well as more traditional TSF methods. It’s important to note that these results cover the transformers’ zero-shot forecasting capability, so no additional training has been done. In terms of accuracy, their own TimeGPT and Google’s TimesFM outperform the foundation-based and classical alternatives while having inference times very similar to methods such as seasonal naive. As for the other foundation models, Morai does not beat the statistical methods and Chronos is significantly slower. But, as you might expect by now, there are multiple discussions and pull requests addressing those performances as well. Find an overview of Nixtla’s findings below.
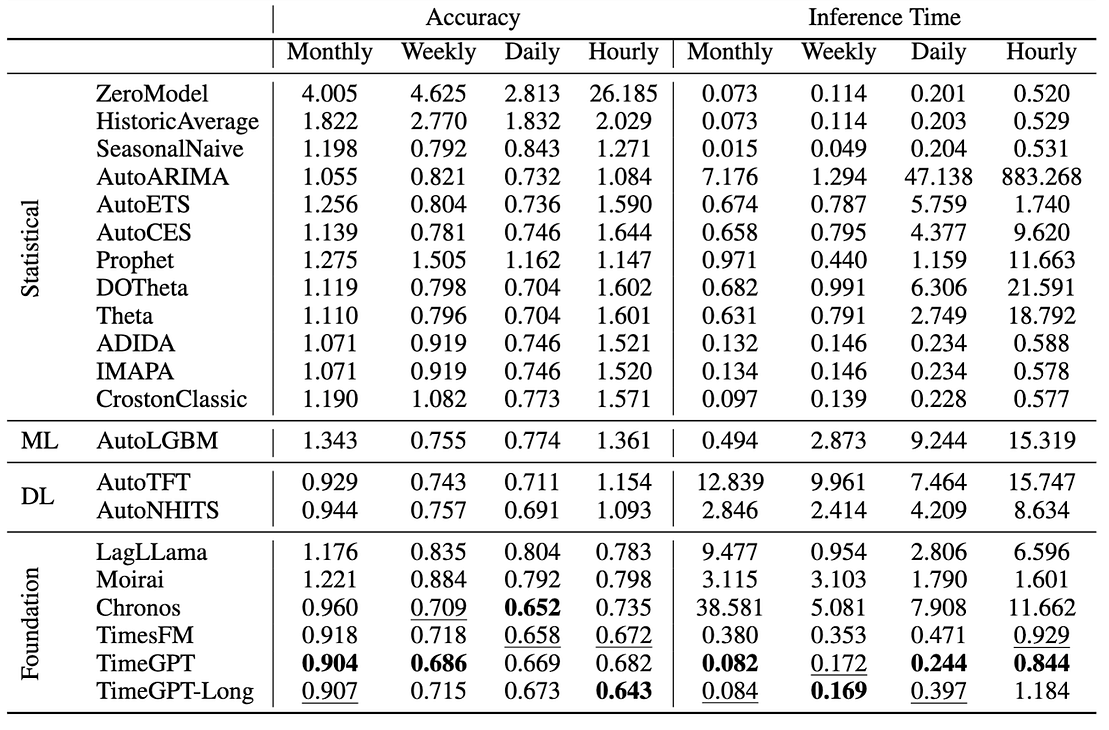
Nixtla’s benchmark for foundation models for time series forecasting
As a final point, there are the time series forecasting competitions where participants evaluate and compare the performance of different algorithms. A recent example is the VN1 Forecasting challenge, focusing on forecasting sales using historical data. And while the winning submissions look very similar to those of the M5 forecasting challenge (spoiler: they all use LGBM), Temporal Fusion Transformer (TFT), a local transformer-based approach, ranks fourth. In fifth place there’s a combination of LGBM and Google’s TimesFM foundation model. Nixtla’s TimeGPT and Amazons Chronos are absent from the list. Unrelated but still interesting: from the 2800 submissions, a naive forecast secured the twelfth spot.
Thoughts on the future of benchmarking
Before we wrap things up, some thoughts on the current status of putting these models to the test. First, good benchmarks are still few and far between. As a result of rapid experimentation, a lot of papers put forward their own take on the method instead of properly reviewing the already available options — this applies to both research on local and foundation transformers. That being said, this phase of quick iterations will pass over with time, leading to more consolidation and deeper evaluations of existing approaches. Furthermore, including more traditional (baseline) TSF methods should be encouraged. Deciding transformers as the method of choice should be justified by better performance compared to simpler alternatives, rather than just outperforming other transformer-based solutions. Furthermore, in addition to forecasting, benchmarking these models should include applications such as outlier detection, event forecasting and probabilistic forecasting. Finally, for some of the foundation models the training data is not being disclosed, making testing by the community very difficult due to the risk of overfitting. As long as it remains unclear whether any potential testing data could have been part of the training data, benchmarking these models will remain a challenge.
Conclusion
Based on the recent surge in papers and their performance, it seems the future of transformers in TSF is heading towards foundation models. This is interesting from both a modelling and engineering perspective. The former because foundation models promise a favorable trade-off between accuracy and quick results. The latter because of how these models are being made available, for example through an API or sharing the model weights.
While foundation models are not the new golden standard and remain contested, they seem to evolve into possibly useful tools in the time series toolbox based on recent benchmarks and competitions. Another point to keep an eye out for is testing these models with additional fine-tuning efforts or when stacked together with more traditional methods, as could be seen in the VN1 competition. These findings could ultimately shape how we integrate transformers into our forecasting practices, revealing their true capabilities and positioning in the evolving landscape of time series analysis. For additional reading on transformers in TSF problems, please see the links below.
- Comprehensive survey of time series transformers
- Original paper on Amazon’s Chronos
- HuggingFace paper on the renewed interest in recurrency: Were RNNs All We Need?
- Under the hood of Picnic’s demand forecasting model: A Deep Dive into the Temporal Fusion Transformer