Enterprise Patterns in Go: Lessons Learned Through Oldschool Data Platforming
A Personal Journey Transitioning from Lambda Functions to On-Prem Data Engineering

Rasmus Renvall
My role for the last many months has been contributing to a project which manages various data services for Scholt Energy here in the Netherlands. This involves mostly building and maintaining data collectors, publishers, APIs: classic data engineering tasks. With previous experience in the industry on exactly this kind of thing, I had high expectations and was ready for some high velocity from the beginning. The project in question is primarily written in Go: even better! I had spent some time in months prior learning Go, and I was ready for to put my newly acquired skills to the test.

For some context, most data tasks I’ve done previously were done with AWS lambdas written in Python. Very much a “Ship first, structure later” mentality more often than not. As a part of my professional development, I started experimenting with writing some of these in Go. Some of Go’s native features made these tasks much easier: struct tags and the native library alone makes most tasks involving collecting data from an API completely trivial. Combining that with Go’s speed and its easy cross-platform compilation (fun fact, Docker, Kubernetes, all the heavy-hitters in containerisation, are written in Go!), it’s a natural contender for this sort of process.
What I wasn’t prepared for was encountering a data collection project that wasn’t just a collection of scripts. Instead, I was presented with a large monolithic codebase where data collectors, publishers, and APIs all ran as long-lasting services. The project embraced enterprise patterns I knew primarily from Java — dependency injection, complex configuration management, factories, builders, plugin-style extensions on services, extensive testing, and careful state management.
In my time browsing Go communities and forums, I’ve seen mostly critical takes on this style of software engineering. For every article I’ve read describing layered architectures in Go, there was always a slew of responses describing why it was “unnecessary”, or why Go isn’t suited for these patterns, and warnings for every new Gopher to not bring “bad” habits over from their previous language experience. It doesn’t take long to find Go developers having discussions on their subreddit or other programming spaces online with takes such as “Why Clean Architecture and Over-Engineered Layering Don’t Belong in GoLang” or comments saying that needing to create 7 files before you can actually get anything started takes away from the core philosophy of Go. “Go isn’t Java” is a phrase I’ve probably seen dozens of times in forums at least.
In this case though, the patterns were already set. Gopher-subreddit be damned, this project had enterprise design patterns all over, and I had to learn how to make things work. In this article, I hope to give some insights on what working on a project following these paradigms feels like in Go, how it compares to “traditional” Go idioms, and lessons I learned which I’ll take with me going forward in my career.
From Serverless to Self-Managed: Understanding Hidden Complexity
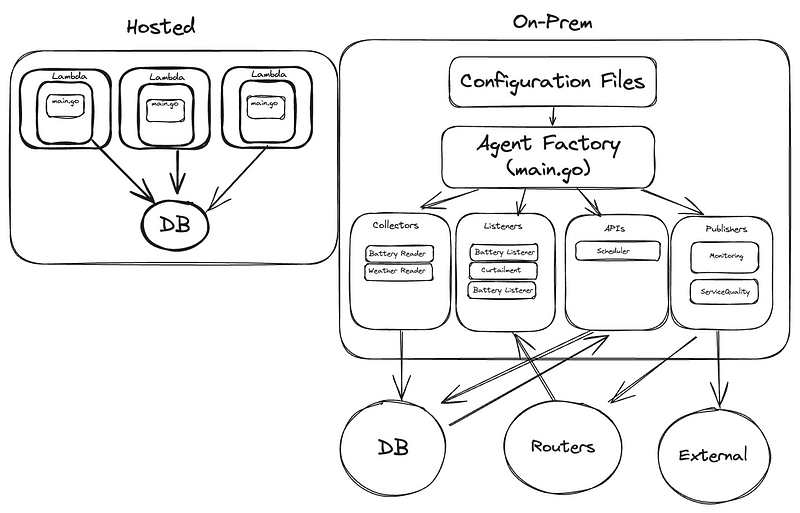
Comparison: Mental Load when Designing a New Service
Head in the Cloud(s): The AWS Lambda Experience
With a collection of AWS Lambdas as your Data Collection strategy, the flow for any given task was quite simple. You probably had a client, some sort of basic transformation to format the request you wanted, perhaps some sort of custom unmarshalling or further transformation of the response you receive, and then a call to store it in your database. Something probably not too dissimilar to this:
func collectBatteryData() error {
client := api.NewClient(os.Getenv("API_KEY"))
readings, err := client.GetBatteryReadings()
if err != nil {
return err
}
return database.Store(readings)
}
Perhaps there’s something interesting in your database.go and client.go in your project with some helper functions defined, and all of them get called together in your main.go, and happy scraping! If you need to scrape from another endpoint, just repeat the process: Copy and paste most of your boilerplate, and write a different function in a new client.go in a whole new Lambda. Who cares about DRY principles when Go already has you repeating
if err != nil {
return err
}
every few lines anyway? (I’m kidding now, but this mindset still comes back to haunt me when I find myself lost in multiple levels of abstraction) Note: Go 1.24 might have a way around this, in case tedious error handling was putting anyone off from trying Go out.
Looking back, I see now that I was actually quite… spoiled. With AWS, most things I might have to worry about (outside of a pet project…) in a Data Collection task are taken care of for me. Transforming the data was pretty much all I had to worry about! Between Lambda and Cloudwatch alone: monitoring, logging, tying together with other services, all handled by AWS.
Keeping code simple and clean when all of the complexity is handled for your through your infrastructure is easy! With Go, everything is even faster and simpler. Go’s native library has most things out of the box, deployments can be kept nice and small: happy days.
Head Out Of The Cloud(s): Building Our Own Infrastructure
Back to earth, and, our big Monolith.
When I first saw the project, I immediately saw many of the things that the Go community had warned me about: multiple layers, abstractions all over, multiple levels of configuration, deeply nested modules. Factories, mocks, builder patterns, adapter patterns, amongst others.
At first, I was quite jaded. I assumed this must be those pesky Java developers coming into Go trying to force their Object-Oriented ways into our beautiful non-object-oriented language. Go is *simple*, remember? Don’t introduce unnecessary complexity. Someone who tried to challenge this (and was rejected) writes:
“They are clearly afraid of classes. As in, if you believe in classes, you put at risk their entire belief system. To reach Go nirvana, one must renounce his/her object-oriented past. And one must accept that grouping methods based on their receiver type is blasphemy.”
I love being jaded and judgemental (I’m a millennial, after all), I found myself very much embracing the idea of Go and all of the Gophers *in theory*, but now it was time to get working with Go *in practice*. And, in practice, you’re going to come across a project that doesn’t fit your vision of Go-enlightenment some day. While I love to look at any complexity and write it off as unnecessary complexity, sometimes things actually are complex, and your solution is going to have to reflect that.
Without AWS, I was now reminded what a fully on-prem Data Platform looks like. I was used to blissfully overlooking the overhead taken care of for me: monitoring, batching, how to handle retries and scheduling — now each required our own hand-built solutions. Not unnecessary complexity at all, it was actually all very much necessary! Once you’re past a handful collectors or APIs, you’re not simply going to go through your logs every day to make sure things are fine. A new way of scheduling, a new monitoring practice, a new data transformation to apply to multiple collectors: these all become quite tedious if you’re needing to apply code changes to each service across your project.
A classic case of scaling and project maintenance.
The project’s solution to these problems was a lot of practices and paradigms which I had never used, at least in such a hands-on matter. Most of the time, the framework or platform I was working with had some way to handle this complexity for me. Instead of individual scripts, everything in this platform was built around a plugin-based architecture with multiple configuration layers. Behaviours were defined once and configured many times — monitoring, metrics, data processing all lived at different configuration levels. Want to add a new collector? Define its configuration and implement required interfaces. Need to add new processing logic across multiple collectors? Create the processor once, add it to configurations where needed. No need to modify each collector’s code.
Configs and Plugins All The Way Down
Quite a few of my commit messages on this project follow some variation on the theme of “got lost in configs again”. Without getting too lost in the details, the project has:
- An Agent module, which has a “model” defining the sorts of over-arching configurations something can have. Big changes or entire new behaviour types will have some changes here.
- A Configuration module, which contains *a lot* of various models and objects that are returned based on what elements are present in an Agent’s set of config files.
- The rest: Metrics writers, Processors, modules holding models for the unique data shapes for any particular data provider, database modules, security modules. Each module at this “lower” level will have some version of its own configurations as well, which will get nested in a higher up Agent-level configuration at some point.
Admittedly, this was very hard to follow at first. Each collector seemed to do quite a lot, but I couldn’t *see* where all of this happened in the code, in most cases. Often I saw changes in the behaviour of our services, but without seeing any pipeline runs or code changes. Was this an example of that over-engineering that the Gophers warned me about? With Go being so easy, would it really be that big of a problem to actually just *write* the behaviours I want to implement every time?
However, I decided that it was better for my development as an engineer to trust the project as it was and use it as a learning opportunity. After some time I was able to appreciate the separation of concerns, and the lack of rewriting or repurposing of existing code. A new collection service for a particular data provider generally had a slower start, but much easier maintainability and extendibility. Adding a new collector to a particular service, when done right, just came down to adding a new configuration file in our deployment, probably a new struct in our DTO, and maybe an extra “switch” in our collector if there was some particularly unique processing to be done for this particular addition to the service.
It took building a few services before I started to get the hang of approaching building collectors this way. However, all it took was a few publishing errors and needing to dig through a few days-old logs to check where I had to configure historical re-runs to appreciate that a little bit of engineering can save a lot of time in the quite-near future.
Perhaps the most basic example: assume that collecting from a particular source requires a “from” and “to” time. In a service-based approach, a simple addition is to only update your “from” on a successful run. This means that next time your service gets called to collect, it will be reading from a “wider” from/to interval, automatically filling what would have been a historical gap in your data previously.
//Create a structure to "hold" the state of from/to for the next run
type CollectorPeriod struct {
from time.Time
to time.Time
period time.Duration
}
func (this *CollectorPeriod) From() time.Time {
return this.from
}
func (this *CollectorPeriod) To() time.Time {
return this.to
}
// and add to collector definition!
type Collector struct {
client Client
converter Converter
builder Builder
auth Authenticator
period CollectorPeriod
config CollectorConfiguration
}
/* etc. etc... */
func (ec *ExampleCollector) Collect() error {
...
...
ec.client.GetBatteryReadings(etc, etc. period.To, period.From)
period.To.Add( {your time interval} )
if err != nil {
return err
}
// From only gets updated if we get here, meaning the run itself went fine
period.From.Add ( {your time interval } )
return nil
}
One small step towards a much more robust collection service already. This same idea gets extended to just about every aspect of what happens in any collection service. After enough time, what I initially “lost” in initial development or prototyping time, I gained back quickly in these services being more robust and easier to change once they were up-and-running.
It took a few tries to get used to which moving parts of a service could be better served as an element in a configuration. Source names I’m reading from, routers I’m publishing to, how to handle date/time ranges, scheduling, etc. At first, I was starting with something very prototype-y, and once I got a service with a basic configuration together, I then would try to rewrite it where I replace some fields or attributes with things I might be able to read in from a config file. It was quite clunky at first, and I very much *felt* the tradeoff between fast scripting and prototyping vs the time it takes to build my code through the lens of the paradigms set in the project.
Turns out there was something else going on here that I didn’t appreciate at first. All this configuration flexibility, this ability to swap components and behaviours without changing code — it was built on one of Go’s most powerful features: its interface system. While the configuration layers gave us the “what” of our services, Go’s interfaces gave us the “how.” And that’s where this project started to feel less like “Java in Go” and more like Go playing to its strengths.
Interface Design: Where Go Shines in Clean Architecture
Go’s interface system works quite differently from what you might be used to coming from languages like Java or C#. In Go, interfaces are implemented implicitly — often called ‘duck typing’ (if it walks like a duck and quacks like a duck…) This means types don’t need to explicitly declare which interfaces they implement. This is quite unique to Go, giving it the flexibility that we usually see in Dynamic languages while giving us the performance and type-safety of a compiled language.
I’d highly recommend checking out some articles about Go’s interfaces; the differences are subtle but very powerful.
A basic example would look something like this:
// Common behavior for all readings
type Reading interface {
GetTimestamp() time.Time
GetDeviceID() string
ToTimeSeries() TimeSeriesData
}
// Different types of readings
type BatteryReading struct {
DeviceID string `json:"device_id"`
Timestamp time.Time `json:"timestamp"`
Power float64 `json:"power_kw"`
}
type BatteryValidation struct {
DeviceID string `json:"device_id"`
Timestamp time.Time `json:"timestamp"`
Frequency float64 `json:"frequency_hz"`
Voltage float64 `json:"voltage_v"`
}
// Both types implement Reading interface
func (b BatteryReading) GetTimestamp() time.Time { return b.Timestamp }
func (b BatteryReading) GetDeviceID() string { return b.DeviceID }
func (b BatteryReading) ToTimeSeries() TimeSeriesData {
return TimeSeriesData{
Measurement: "battery_reading",
Tags: map[string]string{"device_id": b.DeviceID},
Fields: map[string]interface{}{
"power": b.Power,
},
Timestamp: b.Timestamp,
}
}
// BatteryVaidation implements the same interface
func (v ValidationReading) GetTimestamp() time.Time { return v.Timestamp }
func (v ValidationReading) GetDeviceID() string { return v.DeviceID }
func (v ValidationReading) ToTimeSeries() TimeSeriesData {
return TimeSeriesData{
Measurement: "battery_validation",
Tags: map[string]string{"device_id": v.DeviceID},
Fields: map[string]interface{}{
"frequency": v.Frequency,
"voltage": v.Voltage,
},
Timestamp: v.Timestamp,
}
}
Now that both of these structs implement the “Reading” interface, I can create a function which takes in any sort of Reading as an input and process them similarly. This allows me to avoid needing to have multiple different implementations in my Builders for different data types, and I now have a “skeleton” of what any new kind of reading will need to look like.
One of the most common places you’ll see this happen is Unmarshalling JSONs. If the API we’re scraping happens to give us exactly the datatypes that we want, thanks to Go’s struct tags, it really is a simple as this:
//dto.go
type DeviceAvailabilityResponse struct {
ID int64 `json:"id"`
From time.Time `json:"from"`
To time.Time `json:"to"`
Power float64 `json:"power"`
}
//client.go
...
...
/* set up call, get response */
defer resp.Body.Close()
body, err := io.ReadAll(resp.Body)
if err != nil {
return DeviceAvailabilityResponse{}, err
}
var result DeviceAvailabilityResponse
//Unmarshal can work on any type that has an UnmarshalJSON method
// which has a default behaviour; but can be "overridden", seen
// in next example
err = json.Unmarshal(body, &result)
if err != nil {
return DeviceAvailabilityResponse{}, err
}
return result, nil
}
However, when collecting data from APIs, we often encounter situations where the raw JSON data doesn’t match our ideal structure, or where we need to perform validation or transformation during the unmarshaling process. In that case, we only need to add this little snippet referred to from above:
func (ar *DeviceAvailabilityResponse) UnmarshalJSON(data []byte) error {
var raw struct {
ID int64 `json:"id"`
Power float64 `json:"power"`
From int64 `json:"from"`
To int64 `json:"to"`
}
if err := json.Unmarshal(data, &raw); err != nil {
return err
}
ar.From = time.Unix(raw.From, 0)
ar.To = time.Unix(raw.To, 0)
ar.ID = raw.ID
ar.Power = raw.Power
return nil
}
And our client doesn’t need to do anything differently! Because our AvailabilityResponse implements the Unmarshaler: it’s definition is simply something like this:
type Unmarshaler interface {
UnmarshalJSON([]byte) error
}
This same principle holds in the bigger picture of a larger service-building framework. Once we’ve defined behaviours that we can safely assume will hold common across multiple services, we can simply abstract them out to create larger compositions of components.
Say we have web services that handle things like accounts for an API, and collector services which keep behaviours such as metrics building. This might look something like this:
type CollectorConfiguration interface {
GetName() string
GetInterval() time.Duration
GetMetricsEnabled() bool
}
type EndpointConfiguration interface {
GetBaseURL() string
GetTimeout() time.Duration
GetAccount() security.Account
GetRetryCount() int
}
// Our specific collector needs all of these capabilities
type OurOwnExampleCollectorConfiguration interface {
// must implement ALL methods from these interfaces
// which can be done by just adding their structs to our
// new app struct. Composition!
CollectorConfiguration
EndpointConfiguration
// Plus its own specific methods
GetCustomParameters() []CustomParameterSet
}
Now in our actual implementation, we have everything structured for us when it comes to basic behaviours, and we just have to remember to go back to our custom configuration whenever we find a new behaviour specific to the service we’re building. If you suspect this is something that might eventually become common for future services, move it up in the chain, and a future collector will have the behaviour you want adding nothing more than the right fields in some configuration files!
So after a lot of adaptation on my part and a few servings of humble-pie, I found myself quite impressed with how well Go can handle creating services or applications made up of a bunch of moving parts.
Lessons Learned: When to Embrace Complexity
As previously mentioned, it seems like the average “Gopher” seems to not like these approaches. In their minds, it takes away what is meant to be ease-of-use and seamless developer experience of Go. 1:1 mappings of code:behaviour feel great, and it does make it easy to pick up a new project when nothing is hidden from you. Being introduced to a project with more plug-in style and config-heavy approaches to behaviour was a huge contrast to all of the Go-code I had ever been introduced to before. After something like 6 months, how do I feel now?
Honestly, I learned to appreciate the value that these practices bring. The learning curve was indeed quite steep, and I originally felt like I wasn’t really writing “Go”. Some tasks which initially seemed quite simple had me tripping up over multiple levels of abstraction or not being sure when I needed to implement something new, or if there was something already in use somewhere that I could simply embed into the service I was building.
Overall, I feel that I grew as an engineer, and I even managed to develop some quick wins. For instance, when stakeholders requested changes to existing collectors, I often found myself making simple configuration adjustments rather than modifying code. In more than one instance, adding a new collector to a particular provider was just an additional config file. Or one change managing to fix a bug that existed across multiple collectors. As I get used to it, I’m able to take a much more mindful and careful approach to something like a data collector, when before my mind only went to that level when it came to much working on a much larger project.
I didn’t appreciate it fully at first, but after the initial learning curve, it really ended up feeling like using an external service again, to bring this comparison back full-circle. Turns out that a little bit of interfacing and composition takes care of quite a lot of what happens behind the scenes on a larger data platform! A little bit steeper of a learning curve, but with the benefits of being able to extend to using just about any behaviour I want, as we’re in control of the whole platform from end to end. Sometimes simplicity is an illusion, and what sounds or feels simple is actually a matter of a lot of complexity being taken care behind the scenes. By contrast, sometimes complexity is *also* an illusion, and it’s a matter of approaching the problem from a different direction.
“The complexity of a system is proportional to the complexity of the problem it solves.”Fred Brooks
Conclusion
I’m sure that going forward, I’m going to be able to carry some of these lessons and experiences into many more projects that I come across. These are considered “textbook” for a reason, so I’m sure I’m going to see these patterns more often the more projects I get exposed to. Seeing them through as many lenses and interpretations as possible will only make it easier for me to adapt to them in the future.
Do the Gophers and these Anti-Enterprise types have a point? Maybe sometimes. There are definitely some places where the processes in place are so simple that even if you need to rewrite them completely, it might not take much time at all, and almost any level of engineering can be considered over-engineering.
However, I think Go actually handles these “enterprise” patterns or clean-architecture approaches quite elegantly, and it’s worth working on your engineering chops to know how to use them in any language that you come across. Interfaces in Go are extremely powerful, and quite easy to get varying degrees of “wrong”. Patterns serve the code, not the other way around. You’ll usually learn something worthwhile if you try to do anything in an unconventional way.