Understanding inverse propensity weighting
Today I’d like to explain the underlying concepts of Inverse Propensity Weighting (IPW). As a Machine Learning Engineer, it’s important to know how models and algorithms work. This allows you to determine when approaches work and understand why they might not work. You need to really grasp the structure, concepts, and behavior of every approach I use. Getting something to work is nice, but you need to understand it thoroughly to have confidence in the model output. Getting to this level of understanding is a habit I’ve formed in all my technical work.

In a previous post I’ve explained how inverse propensity weighting can mitigate bias in modelling treatment effects.
The bias is caused by treatments not being randomly assigned. This happens when there are variables that influence both the treatment assignment and the treatment outcome. In that case, the effect of the variable can incorrectly be (partly) assigned to the treatment, resulting in a biased model.
Inverse propensity weighting is an approach where the treatment outcome model uses sample weights. The weights are defined as the inverse propensity of actually getting the treatment. This will remove the bias from the model, but why?
To see why this approach works, we will walk through the approach step by step:
- First I’ll shortly recap the modelling situation, including how the transformed outcome is used.
- The next step is creating an artificial data-set that will cause a naive model to be biased.
- Next, I’ll fit that naive model, to show that it is indeed biased.
- Then I’ll continue creating a non-biased model. To do so I first need to create a propensity model (predicting the likelihood of getting a treatment)
- Then we can construct a non-biased model, using the propensity model to define the weights. I’ll show that this model is (less) biased and explain the practical difficulties in training such a model.
Predicting conditional treatment effect (uplift) using transformed outcome & inverse propensity weighting
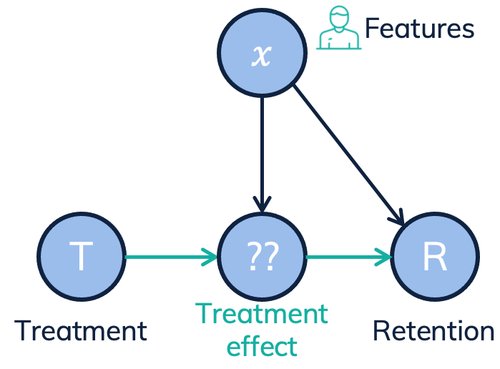
My journey into inverse propensity weighting started when I needed to model retention. There are different actions (called treatments) that we can do to retain customers (prevent them from churning). We can give them a discount, free upgrade, or call them to discover how we can help them. For some it might help, some might even leave because of this action. The challenge therefore is, who can we treat in such a way that we retain them?
We can model this as a classification problem by defining ‘being retained’ as ‘being retained for 3 months’. Customer features go in, together with a ‘treated or not’ flag, and ‘is retained’ comes out. Unfortunately, this doesn’t give us the expected effect (uplift) of a treatment to a certain customer.
As I explained in the blog-post Preventing churn like a bandit, one approach is to transform the model using ‘transformed outcome’ to a regression problem with uplift as output.
The transformed outcome trick assigns labels of either -2, 0, or 2 to samples. These specific values are based on the assumption that there’s a 50% chance of being treated. The inverse propensity weighting balances the distribution out, allowing us to use these labels.
Transformed outcome formula and results
A challenge with most real-life data-sets is that treatments are not randomly assigned. This produces a bias in the data-set, causing the predicted uplifts to also be biased. One approach to resolve this, as mentioned in the intro, is to use inverse propensity weighting (IPW).
Thus IPW sounds like a good plan, but can we get a grasp on what’s happening? And what does the model actually predict? Let’s continue with an artificial data-set, and model both the naive approach (without IPW) and the improvement with IPW. For the latter, we’ll also have to create the propensity model.
Biased data-set
The goal is to show how modeling techniques behave under the effect of biased data. We create a data-set of which we know the ground truths, allowing us to verify the results. I’ll use one single feature x to keep the data-set as simple as possible. To make the data-set interesting enough, I’ll use three underlying distributions:
- Firstly, the reward of the treatment depends on the x value. The difference between the reward for a treated vs non-treated (the uplift), is also dependent upon x. Thus the treatment effect depends on x.
- Secondly, the observations are not uniformly distributed across x. In our case, the samples with higher uplift are observed more likely than those with lower (or negative) uplifts. This adds a sample selection bias.
- Thirdly, the probability of getting the treatment is also not uniformly distributed across x. In this case, samples with higher uplift are more likely to get treated than those with lower uplifts. This adds a treatment assignment bias.
The resulting dependencies are visualized in the following causal graph:
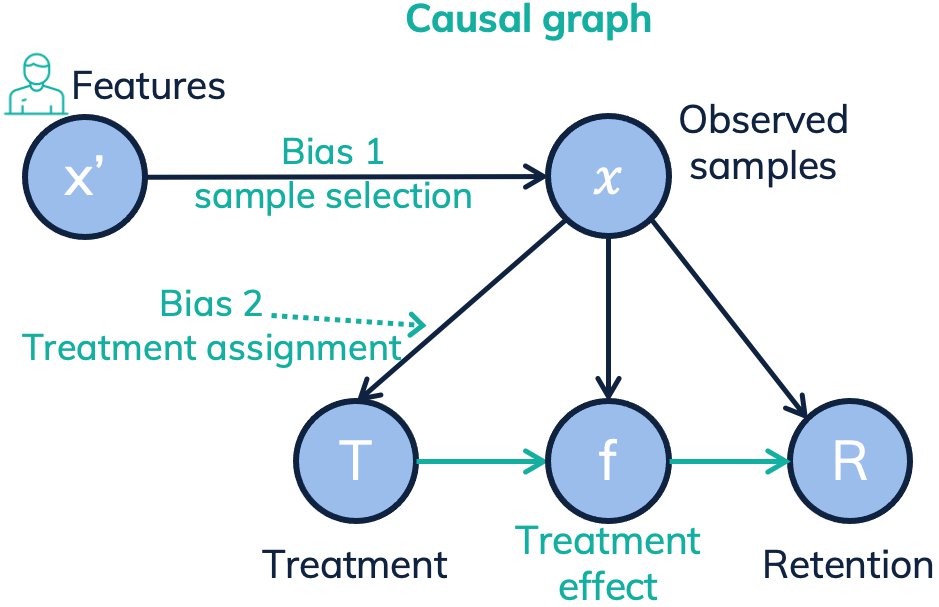
Causal graph showing the introduced biases and dependencies
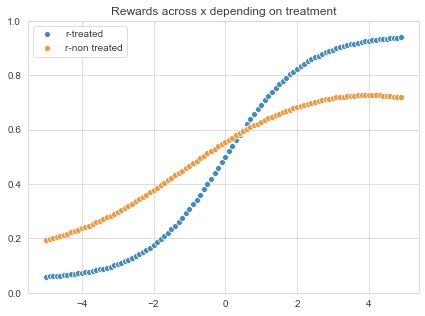
The following plot shows the relationship of rewards to the value of x: P(success | treated, x). The higher x, the higher the likelihood of a customer being retained. The treatment effect (the difference between non-treated to treated) also increases with increasing x.
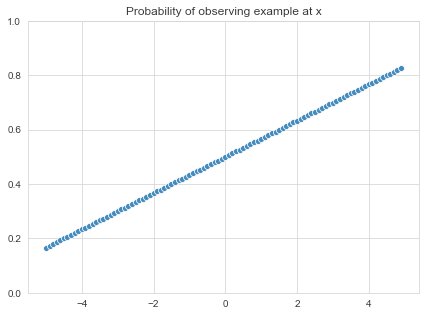
I first introduce the sample selection bias, defined by the propensity P(x). We create a bias in the data-set that magnifies the positive rewards by giving the higher values of x more weight. A measured average success ratio for the whole sampled set would therefore overestimate the true average value of success.
The second introduced bias is that the likelihood of getting treated depends on x, thus treatment assignment bias P(treatment | x). We again increase the likelihood of getting a treatment for higher values of x, that also have a greater success rate. We are now biased towards the more successful action (treatment or no treatment). Simply measuring average uplift per x will thus overestimate the true uplift for that x if it is positive because we'll observe more (successful) treatments.
To see how these biases combine, let’s look at some density plots of treatment propensity and retention propensity. Note, these show how often certain propensities occur.
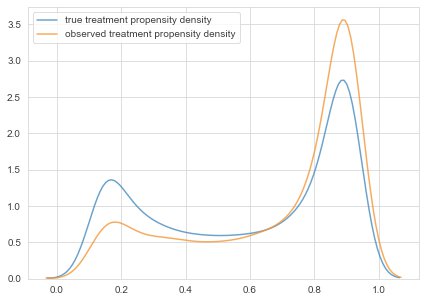
The density plot of the treatment propensities, both of the original data-set and the observed subset.
In this setup, treatments seem more effective than they really are. People for whom treatments are effective, are more likely to get a treatment. Now, let’s see if we can still predict the actual effects even with those underlying biases.
Regression model on the transformed outcome
The outcome in the data-set are sampled labels equal to retained or non-retained. They are transformed to regression labels as follows (with treatment flag T and retained flag Y)
outcome = np.zeros_like(Y)outcome[(T==1) & (Y==1)] = 2outcome[(T==0) & (Y==1)] = -2
The model can be easily evaluated with metrics like RMSE. For extra clarity, let me visualize what’s happening across the feature space. It will show how predictions are biased compared to the ground truth. The following plot shows the predictions across the feature space. For x > -1 it overestimates, while for lower x it underestimates the uplift.
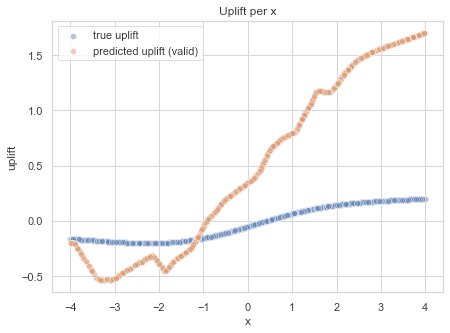
Comparison of the predicted uplift (not using IPW) with the ground truth.
Where is this bias coming from?
Well, the model optimizes its prediction for a certain value of x to the average expected output. The transformed outcome has an interesting effect. Depending on whether or not someone got treated, the label can be -2, 0, or +2. The average should then represent the uplift.
To show that the model is quite capable of predicting that average, let me plot the moving average of the outcome over x.
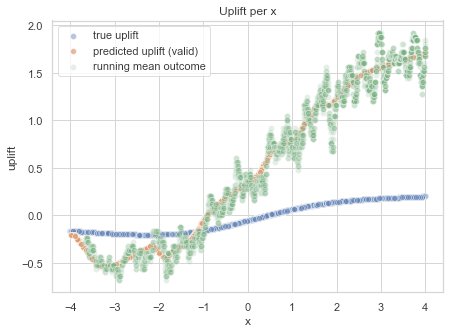
The predicted uplift, compared with the running mean of the outcome.
Our predicted uplift is close to the average outcome for certain x values, but why isn't it close to the true outcome?
As you might have guessed, it’s because of the bias in the data-set. For high x values, that have positive uplift, the data-set has more samples with treatment. Thus the proportion of labels equal to 2 is higher, inflating the mean around that x, that in turn inflates the prediction. On the lower end, the opposite happens (on a smaller scale).
As described in the blog-post Preventing churn like a bandit, applying inverse propensity weighting should correct for this inflation. I will now show how to do that.
IPW powered predictions
Inverse propensity weighting (IPW) means that we include a sample weight in our regression model. The sample weight is defined as the inverse of the propensity of observing that sample (w = 1/P(treated|x)). Thus if for a certain x value we have a sample with treatment and the propensity of getting treated is 20% for that x value, that sample will be assigned a sample weight of 5.
Note that the propensity depends on the local value of x. Thus this approach corrects for local differences in treatment propensities.
To be able to apply inverse propensity weighting, we first need the treatment propensities. In some cases, you might be lucky that those were logged when the treatments were assigned. In practice, you often have a mix of historic policies and only a log of the assigned treatments.
Without logged propensities, we first need a model to predict those propensities. To clarify, we take a model and predict the treatment flag T based on the feature x. In this example, I deliberately regularized the model too much to get a prediction error.
Now, let’s plot the predicted propensities versus the ground truth:
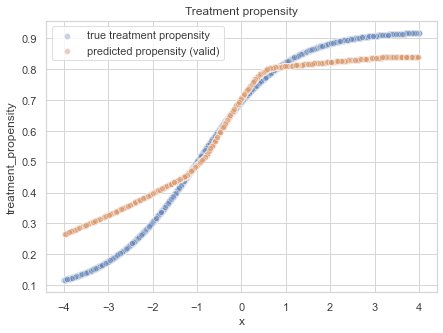
The (on purpose over-regularized) predicted treatment propensities, compared with the ground truth.
Because of the deliberately over-regularized approach, we’re close but not perfect. In this artificial case, we have the luxury to compare the predictions with the ground truth, as we generated the data. In normal situations, one can approximate this by comparing the predicted propensities with observed propensities using a calibration plot. It bins the predicted propensities and then determines the observed propensities in those bins:
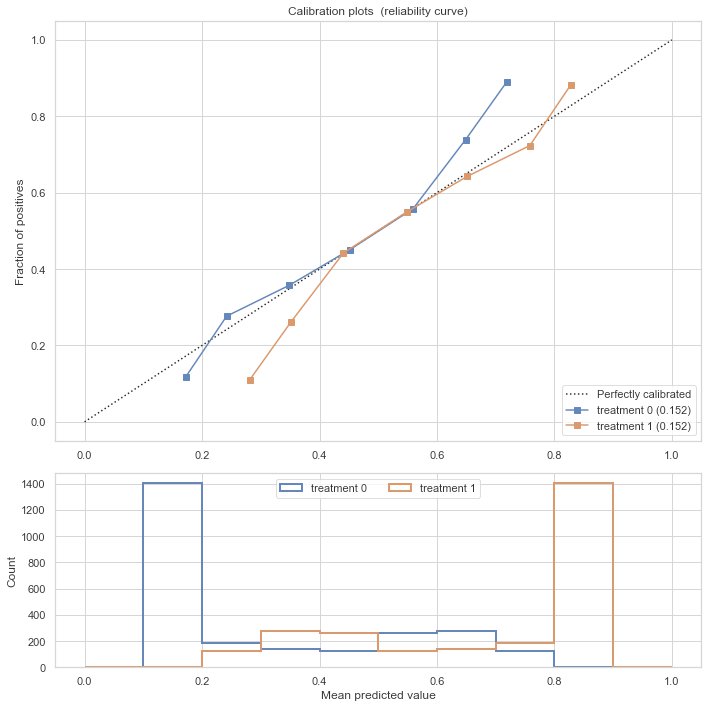
Calibration plot, before calibration of the predicted treatment propensities
With sklearn’s CalibratedClassifierCV we can subsequently calibrate the treatment propensity model. After calibration, it’s almost perfect:
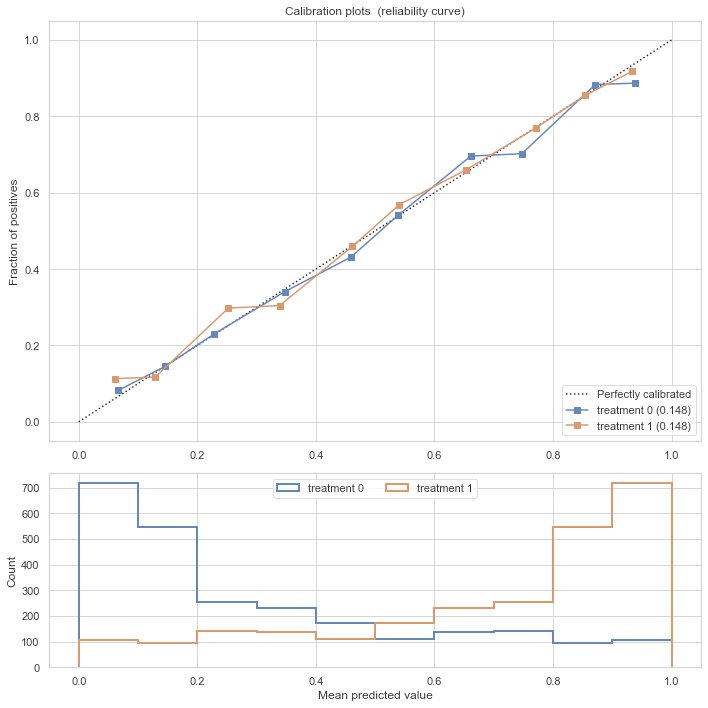
Calibration plot, after calibrating the propensity predictions
If we now recreate the previous treatment propensity plot using the calibrated (and cross val predicted) predictions, it has become much better. The variance on the calibrated propensity originates from the cross-val predict.
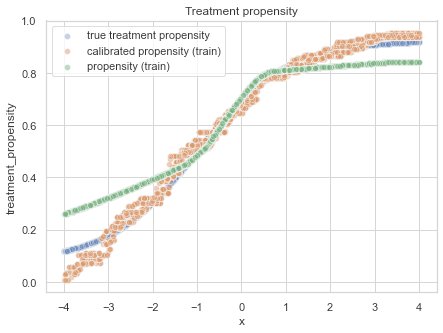
Comparison of the cross-val predicted treatment propensities to the ground truth.
Inverse propensity weighted regression
Predicted propensities will usually not be exactly correct. But near the zero range, a small error can have a huge effect on the weights. Because the weights are defined as the inverse of the propensity, ‘almost zero’ propensities result in practically infinite weights.
To mitigate this effect, it’s a good idea to trim or clip the propensities:
- Either set them to at least a small epsilon, and at most to one minus that epsilon
- Throw the samples with propensities near zero or one out of the data-set.
I’ll demonstrate clipping them to the range [0.05 .. 0.95].
propensities_clipped = np.clip(propensities, a_min=limit, a_max=1 - limit)
weights = 1 / propensities_clipped
# keep sum of weights equal to nr of samples:
weights = weights * len(propensities_clipped) / np.sum(weights)
To know if you are assigning different weights, and aren’t clipping too much, you can plot the propensity densities:
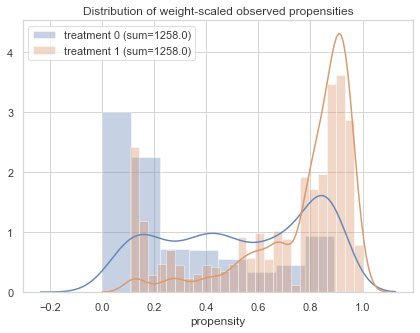
Density plot of the predicted treatment propensities, before clipping.
In our artificial data-set, we don’t have a lot of weights near zero or one. We do see a nice spread between 10% to about 55% for no treatment (and thus 45% to 90% for treatment).
Low regularization
Let’s now fit the weighted model using the same hyper-parameters as for the previous regression model. Fitting the model and applying it to our validation set, results in the following approximation of the predicted uplift.
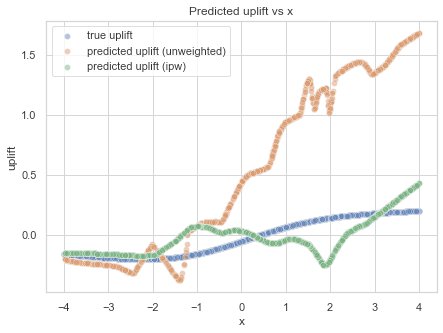
Comparison of predicted uplift with and without inverse propensity weighting to the ground truth (with low regularization).
We might be closer to the true uplift, but we have quite some variance in our predictions. To show where that variance is coming from, we can look (again) at the plot of the running mean. In this case, it’s the running mean weighted outcome:
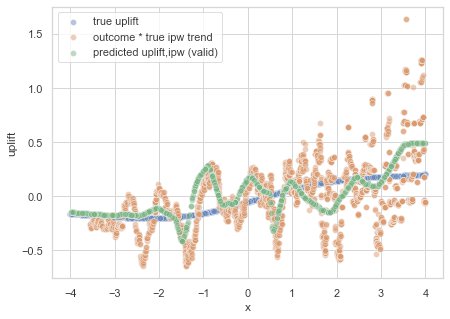
The trend of weighted transformed outcomes shows why the predictions also jumps around.
Well, that explains the jumpy trend (of course, it also depends on the width of the running mean window). The weights thus add variance to the data-set, which requires more regularization in the model.
More regularization
Now let’s add some regularization and fit again. It is a bit hard to get right, as you need good validation sets. In real-life situations, churn percentages are (hopefully) quite low and only a fraction of those will be treated in advance. To get enough treated and non-treated churners in your validation set, you will need quite a big validation set to be able to measure uplift. In our artificial setup, we’re luckier, but it’s still tricky to get the regularization parameters perfect.
Comparison of predicted uplift with and without inverse propensity weighting to the ground truth (with more regularization)
Wrap-up
A model will just predict the mean expected outcome for certain feature values. When using something like the transformed outcome trick, the correct output is thus not equal to the observed samples. The samples have labels of either -2, 0, or 2, but we want the model to predict the mean.
- Therefore, the RMSE will remain high, even though we are perfectly predicting the uplift.
- Because of random processes, one of the three label values can be over-represented a little, or a lot, moving the mean away from the actual uplift.
- These random over (or under-) representations of outcomes are exaggerated by the inverse propensity weights. They adjust the model to the treatment selection bias but introduce more variance.
- This added variance requires that the model is regularized more.
Alternatives
This post has shown how an uplift model can be created using inverse propensity weighting and transformed outcomes. The inverse propensity weighting is especially important in this case, as the transformed outcome assumes that the samples are evenly distributed across treated/non-treated samples. Alternatively, you can adjust the transformed outcome directly using the propensities, which mitigates the necessity of the inverse propensity weighting.
If you need to predict the individual treatment effect, there are fortunately also ready to use packages available, like CausalML (python package by Uber), EconML (python package by Microsoft), CausalImpact (R package by google), pylift (python, a bit older).
Want to read more? My previous blogpost “preventing churn like a bandit” explains more about the general approach.