
Preventing churn like a bandit - with uplift modeling, causal inference, and Thompson sampling
The real goal is to prevent churn, not to predict churn. Thus, we predict the effect of treatments. The transformed outcome technique is helpful. It changes the labels in the dataset such that our model predicts uplift. Reinforcement learning allows us to improve over time. We don’t start from scratch. We use historic campaigns to bootstrap our reinforcement learning setup. That data will have biases. So, we need to distinguish between correlation and causation. The causal inference technique inverse propensity weighting achieves that. We use Bayesian modeling and Thompson sampling to balance exploration and exploitation. That allows us to get quality feedback to retrain the model with. Thus we prevent churn using uplift modeling, reinforcement learning, and inverse propensity weighting.
This article elaborates on what I have presented at PyData Eindhoven (NL) in 2019. Both the slides and the 30-minute talk are available online.
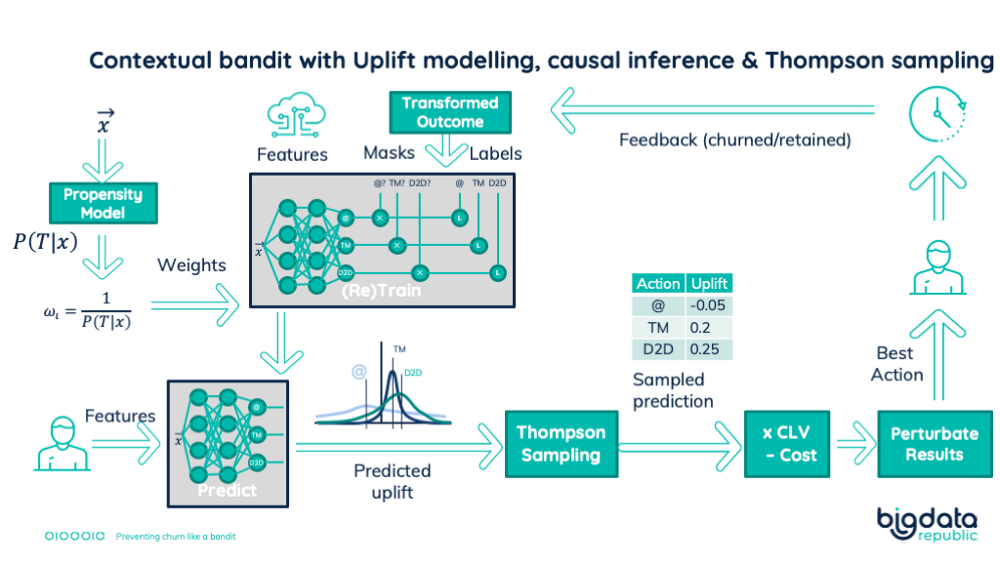
Contextual bandit with Uplift modelling, causal inference & Thompson sampling
Preventing churn
The loss of customers, also known as churn, can have a major impact on your revenue. According to the ProfitWell report of 2019, churn leads to a 2% to 17% monthly revenue decrease. Machine learning (ML) can prevent this, but not every ML solution will be adequate. Some might even be harmful, letting you pursue the wrong path. In preventing churn with ML, I see three important issues to address.:
Take a Telco company. They have different products, like a home internet subscription. How can it retain its diverse set of customers? One single action will not work for everyone. The goal is to give the right treatment to the right customer, to retain as many as possible.
Each business has its specific possible treatments. We can send them an email to give extra information about the product. Or we can call them to find out if there is an issue. We can even visit them in a door-to-door campaign to fix their WiFi immediately. The effect of each treatment depends on the customer’s situation. The goal is to find out which one will retain the customer.
First issue: Predicting churn
As we want to prevent churn, it is a logical step to predict who is going to churn. We then target those who are likely to churn. To determine the best treatment, we could use a different treatment per segment of customers.
This approach separates the goal of preventing churn into two sub-goals. The data scientists determine who is going to churn. The marketing department will determine the treatment that works. Unfortunately, the customers who are likely to churn, are not necessarily easy to retain. They can be so-called lost causes. Predicting churn likelihood makes the challenge of treatment selection very difficult. For some customers it becomes impossible.
Is it that bad?
You might think that these lost causes are exceptions. That this approach only intensifies the marketing challenge. Or worse, that we omit those groups with extra business rules. Ignoring the applied treatments in the model results in a negative effect. Suppose we call some people with a high score and can persuade them to not churn. They will end up in our future training dataset as non-churners. Retraining the model will result in them getting a lower score. Thus we learn to stop calling the persuadable customers.
Now suppose we call some people with a high score and we are not able to persuade them. They are so-called lost causes. The model predicted them to churn, they did in fact churn, and they are future churned training samples. Retraining the model will result in them having a high score. Thus we learn to keep calling the lost causes.
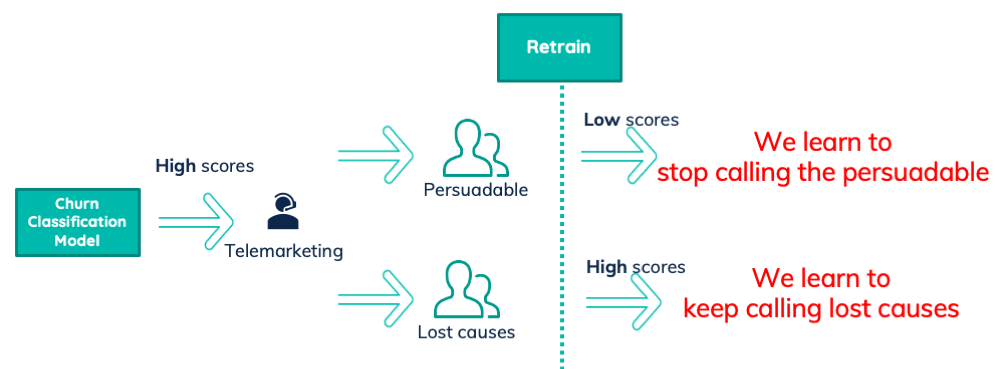
Ignoring treatments in your churn model is very bad.
Instead of predicting churn, we should predict the effect of treatments. Thus we need to predict the churn probability given the treatment they get. Or even better, the retention probability. I’ve explained this further in this blog-post.
Not all treatments are equal. The ‘no action’ treatment is the default choice. As a business, the status quo is to have no treatments. Or at least, not a model predicting which treatments to give. The effort we put into our model should bring significant added value. That added value is the improvement compared to doing nothing. This difference is called the uplift. A more elaborate explanation of why to use uplift is available in this post. Thus we should predict uplift, and then select the treatment with the highest score.
Optimize for business value
Unfortunately selecting the treatment with the highest uplift is not good enough. That selection ignores the different costs of the treatments. Sending an email is for example much cheaper than visiting a customer’s house. Customers are also not equal, they bring in different revenues. To make the best choice, we need to maximize business value.
The multiplication of uplift with customer lifetime value is the expected reward. That reward minus the treatment cost gives us the expected business value. In that way, we get the expected business reward of each treatment and can choose the one with the best value.
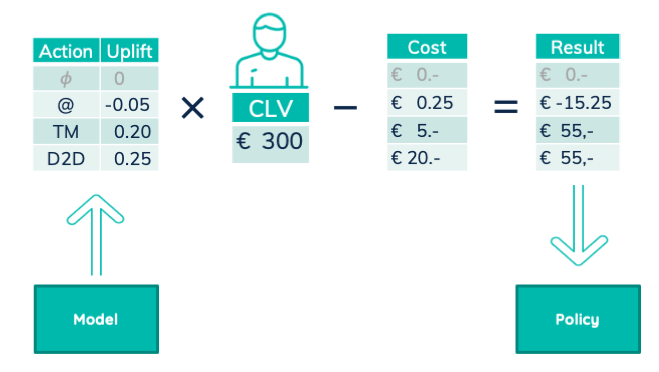
The model predicts uplift. We then combine it with customer lifetime value and treatment cost. The resulting business value drives the company policy.
Note that we are predicting uplift and calculating revenue, instead of predicting revenue. This allows us to change our business processes while holding the model constant. The business can find cheaper ways to call. Or we improve customer lifetime value calculation. If the model would predict revenue, we would have to throw away all data created using old processes. But now we can incorporate all these changes without model changes.
Predicting uplift with the transformed outcome
An easy way to predict uplift is to first predict retention rates. From these retention rates, we then subtract the predicted ‘do nothing’ retention rate. This, unfortunately, increases our prediction error. Every prediction has a certain uncertainty. Combining two predictions results in a summed uncertainty. This approach thus increased the error of our calculated uplift.
It is thus better to predict the uplift directly. Unfortunately, the uplift is not available for each data point we have. The customers only got one treatment. We know if that treatment retained the customer or not. But we don’t know if any other treatment would keep the customer. There is a way we can still assign uplift labels to our dataset. The ‘transformed outcome’ trick derives those labels in a specific way.
The transformed outcome changes our classification problem into a regression problem. We solve this regression problem by minimizing the root mean squared error (RMSE). The labels are being defined according to the following formula. For a random treatment assignment P(W==1)==0.5, this results in 2, -2 and 0.
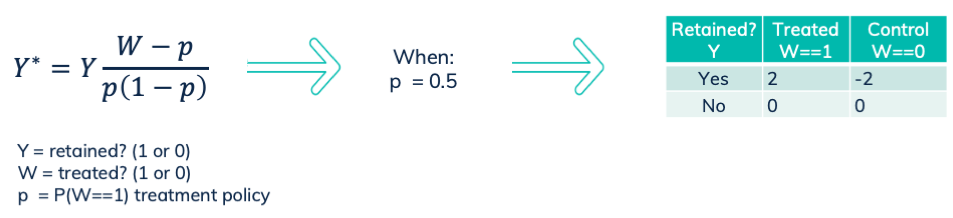
The transformed outcome formula, with resulting labels when treatment propensity is 50%. See this paper.
The transformed outcome in action
Let’s see this work. Suppose we have the same person both in the treatment and the control group. The two instances of that person have the same features. Only one of them got treated. Based on the result, the transformed outcome assigns different labels. The model will need to determine one single prediction as the features are equal. That prediction needs to minimize the RMSE loss for both instances. In this setup, we can distinguish 4 situations.
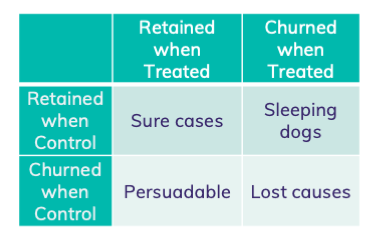
Four cases in treatment data
For a persuadable person, the non treated one gets label 0, while the treated one gets label 2. The point with the lowest RMSE for these two points is 1, which is exactly the uplift.
For sleeping dogs, the non treated gets label -2, while the treated gets label 0. The best prediction would then be -1, which is indeed the uplift.
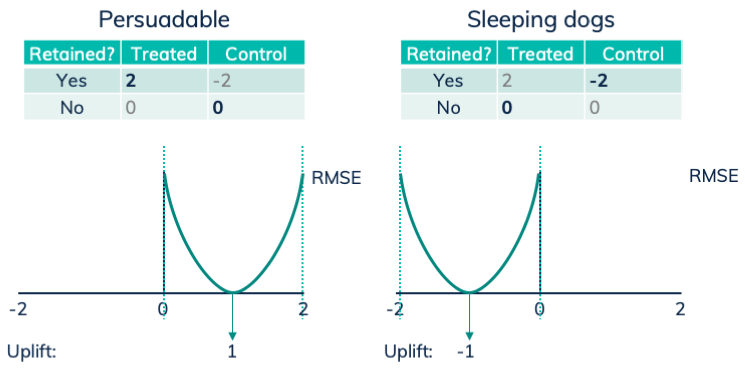
The result of transformed outcome labels: the prediction that minimizes the RMSE is the uplift.
If the person is non-persuadable, a lost cause, both samples will get label 0. In this case, the model has the incentive to predict 0 for this set of features, equal to the uplift of 0.
With sure causes, the non treated gets label -2, while the treated gets label 2. Resulting in prediction 0, again the uplift.
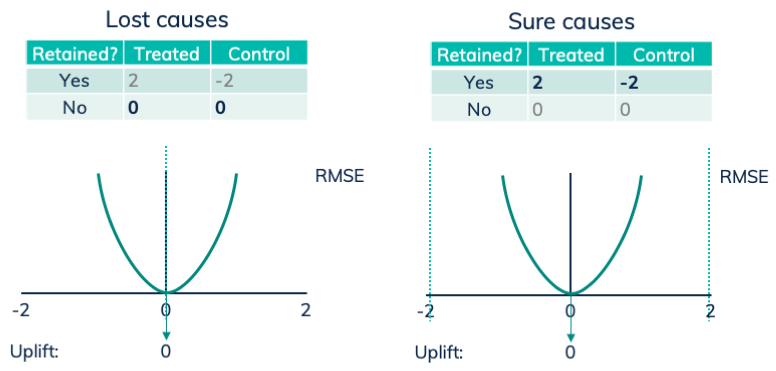
The result of transformed outcome labels: the prediction that minimizes the RMSE is the uplift.
We can extend this setup to two groups of similar people. Then we treat one group, and we don’t treat the other group. This will retain certain fractions of both groups. These fractions result in certain ratios of assigned labels. The model will optimize its prediction to minimize the resulting RMSE. That minimizing point will be the uplift between the treated and control group.
This extension also shows that the treated and control group needs to be of equal size. Otherwise, the RMSE minimizing point will move too far to the response of the biggest group. The treatment assignment probability in the formula addresses that. We’ll solve this later explaining how transformed outcome needs IPW.
Variance of the transformed outcome
Note that the transformed outcome labels are not close to the value we want the model to predict. Take for example the customers of a certain area in the feature space that are ’sure cases’. The true uplift is zero, while the labels are -2 and 2! The model has then incentive to find accidental differences between the samples. The transformed outcome labels thus create higher variance models. It is also good to know, that the optimal loss (RMSE) is not zero! One should add more bias to compensate for this high variance. The techniques depend on the type of model.
Towards reinforcement learning
With the transformed outcome, a fitted model predicts the effect of each action. The observed result of the action will arrive a while later. Our model can learn and improve using that feedback. This is a simple reinforcement learning setup. This kind of reinforcement learning is referred to as a contextual bandit. It is more complex than a straight forward multi-armed bandit. Those have no context for the actions. It is less complex than a full reinforcement learning problem, as we do get feedback per action.
The (multi-armed) bandit setup is named after the one-armed bandit slot machines in the casino. Then there is only one action to do. With many slot machines (many arms), there are many actions. The challenge is to find a strategy of actions that maximizes reward. In a contextual bandit approach, the reward of the slot machines depends on a context.
In a full reinforcement learning problem, we’d be interacting with the environment. The reward arrives delayed, based on all previous actions. In our case, we limit our interactions to 1 action, for 1 person, after which we get delayed feedback.
Our reinforcement learning setup requires two high-quality aspects. First, it needs good predictions of the expected reward. Second, it needs quality feedback to learn better actions. This brings us to the next two issues in modeling churn: correlation vs causation, and exploration vs exploitation.
Second issue: Assuming the correlation is causation
Our model predicts the effect of a treatment. It thus models the causal dependency between treatment and retention rate. In any dataset, we can only observe correlations. An ML model can capture them and then have strong predictive power. But we need prescriptive power. We don’t leave the system operating as it is while predicting what will happen. We are going to change its behavior, by prescribing different treatments. Check this blog-post for more information predictive vs prescriptive in combination with causal graphs.
Let’s start with a simplified case. The following causal graph shows how treatments and features influence the retention rate. In this specific case, the only link between treatments and retention rates is the causal link. We observe the correlation between treatment and retention, based on all paths between them. The only path is the causal link. Thus the observed correlation is equal to the underlying causal dependency.
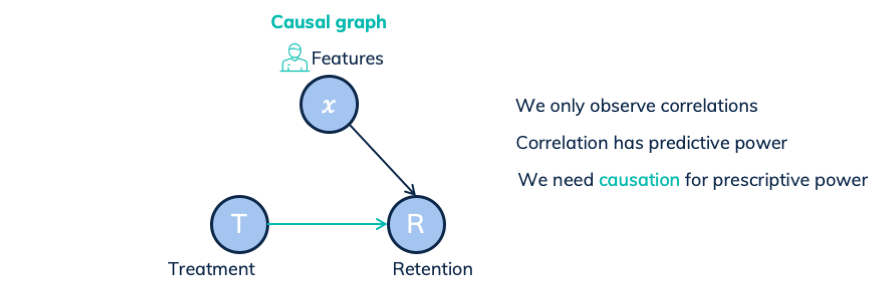
Here correlation is causation
Yet, our situation is different. Past policies determined the treatment based on customer features. The model we are currently creating will do so too. They both introduce a causal link between the features and the treatment. In other words, there is a treatment bias:
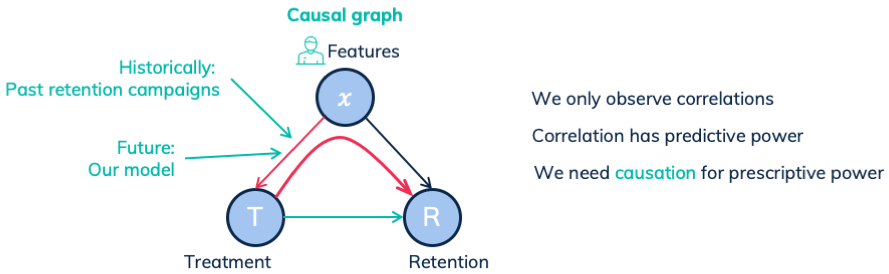
Here correlation is not causation. Because of the confounding features.
Removing treatment bias
There are a few approaches to removing the treatment bias. In general, they are:
- Random trials
With sure causes, the non treated gets label -2, while the treated gets label 2. Resulting in prediction 0, again the uplift. We could gather random data by selecting a few random groups of people. One for control, and one for each treatment. We give each of the groups the corresponding action, and can then afterward fit a model. But this is expensive. We apply treatments to people that don’t need it. We throw away all existing historic data. And we won’t be able to use the feedback we get when our model is running. We go back from a reinforcement learning approach to a classical ML setup. - Modifying features
Another approach is transforming the features in a specific way. The resulting features still predict who we will retain, but not who got a treatment in the past. One approach is to remove the features that best predict the treatment policy. This is explained in a PyData talk available on YouTube.
A little more complex approach is to create an encoding of the features. The encoding model solves two objectives. One goal is to not predict the treatment assignment. The other goal is to still predict treatment effects. This is explained in Learning Representations for Counterfactual Inference by Fredrik D. Johansson, Uri Shalit, and David Sontag, 2018.
Both approaches limit the predictive power. More important, we can only apply both once. We will create a model that uses the modified features to prescribe treatments. When that runs in production, it creates a new dependency from features to treatments. Our goal is to tell the business which treatment to do, based on the features. - Causal inference
The causal inference domain focuses on solving these cases. It might be a bit more complex to grasp, but it targets this specific challenge.
Inverse propensity weighting
One kind of causal inference technique is Inverse Propensity Weighting (IPW). It involves creating a separate model that predicts the treatment assignment. It thus models the correlation — and causal link — between features and treatments. Note that this model has no problem with causality vs correlation since there is no back door. This model then provides us the expected treatment propensities. We use the propensities for the actual combinations of features and treatments that we observed. We invert these propensities and use them as the weights for our uplift regression model.
Let me show different perspectives to see how inverse propensity weighting might work.
In the dataset of the regression model, there is a different distribution of treatments. That distribution depends on the area in the feature space. Re-weighting samples in a dataset is like fractional up- and down-sampling. This changes the local distributions. Then for each area in the feature space, all treatments are equally likely. The weighted density plot across features visualizes that:
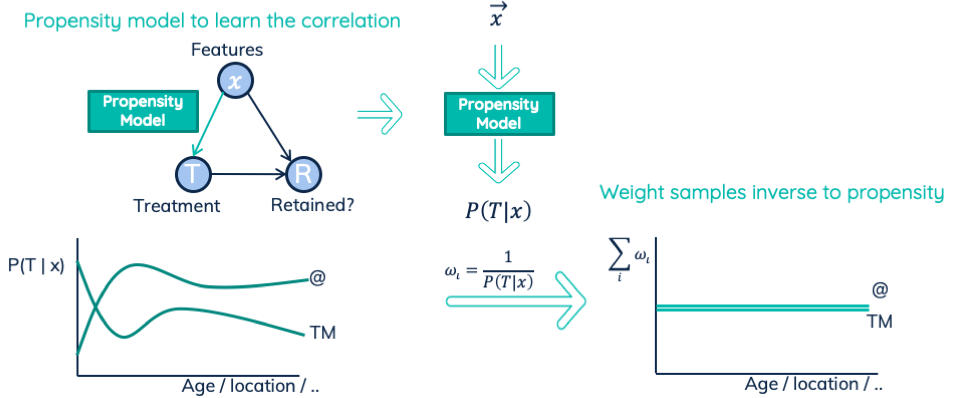
IPW applied on two treatments: sending an email ( @ ) and a telemarketing call (TM). The predicted propensities define the inverse weights.
A second way to look at this is by comparing it to the weighting for imbalanced classes. In the imbalanced case, we want predictions of comparable quality across the classes. Without weighting, we get comparable quality across samples. Re-weighting solves that. Our treatment model should have predictions of comparable quality across all treatments. Re-weighting solved the imbalanced case globally. The inverse propensity weighting setup rebalances locally. Thus within each area of the feature space, the model has the incentive to treat all treatments equal. Balancing every part of the feature space approximately also balances the dataset globally.
A third way to interpret inverse propensity weighting is through information density. Let us take one specific part of the feature space. A part where we have 100 samples who got an email. There were only 10 samples who got a telemarketing call (TM). In that case, we want to put more emphasis on the 10 TM calls. They are rare examples, which can give us unique information. We emphasize the email vs TM by the inverse propensity ratio of 100/110 (email) vs 10/110 (TM). We have 100 samples with weight 110/100, a total of 110, and 10 samples of weight 110/10, also in total 110. Thus the total weight of all email samples is equal to the total weight of all telemarketing calls.
Making inverse propensity weights work
Before we can use the predicted propensities in this way, we need to cover two aspects.
First, the treatment assignment model should have a well-calibrated output. Metrics like AUC measure the ordering of probabilities. In our case, we want the predicted propensities to be close to the actual probability. If the model predicts a treatment propensity of 80%, the true probability should also be 80%. A calibration plot visualizes this, as shown below. If the calibration plot shows (vertical) errors, it can impact the IPW effectiveness. A different model can then help. Or, one can use propensity calibration techniques to adjust afterward.
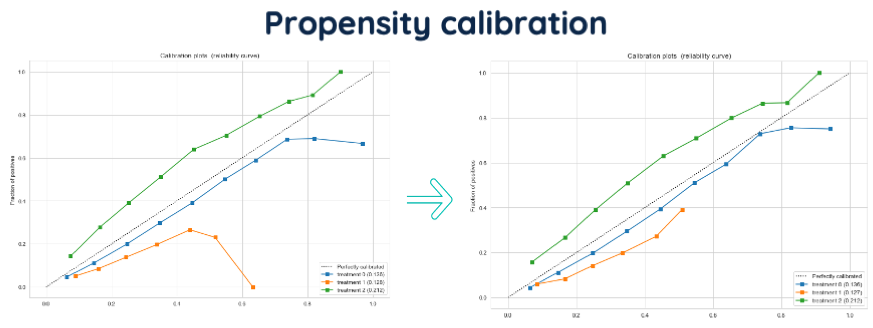
Idea of propensity calibration. Predicted propensities are on the x-axis, observed ratio’s on the y-axis.
Second, in inverse propensity weighting, we divide by the propensity. For propensities near zero, this results in near-infinite weights. This causes the model to over-fit on those few unlikely samples. We can solve this in two ways:
- Propensity clipping.
We clip the values of the predicted propensities between for example 0.05 and 0.95. All values lower we set to 0.05. To keep the expected sum of weights 1, we also need to change values higher than 0.95 to 0.95. - Dataset trimming.
We remove all samples with propensities outside the range of [0.05 … 0.95]. Thus we set their weight to zero.
These infinite weights occur in interesting regions. The probability of being treated was very low (they occur rarely), but we still had some examples. Note the difference between propensity rate and observed frequency. The propensity could be 0.1, and with enough samples, the expected frequency could become 5. Yet, it could just as well be 2.7.
But we can’t observe a fractional sample. We either see none, or at least one. Inverse propensity weight uses the fractional propensity to determine the weight. It re-weights the observed count, which is not fractional. For an infinitely big dataset, the disregarded fraction will be negligible. Negligible compared to the observed samples. For a finite dataset size, the expected fractional frequency can be significant.
Also uncertainty in general influences the inverse propensity weighting. If the expected sample count is 200, there is a probability we only observe 180. The calibration plot errors also include this uncertainty, besides model calibration errors.
We don’t want the noise or uncertainty of a few incidental samples to have too much effect on our result. This especially happens at the lower range of propensity values. Then we’d rather limit their weight (first option), or completely remove them (second option).
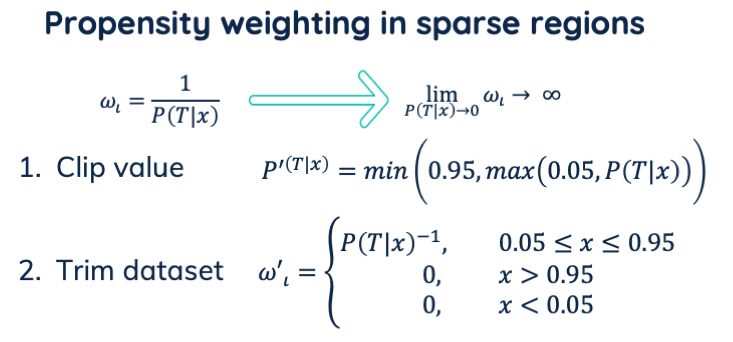
Two possibilities to deal with propensity weighting in sparse regions
Note that this is a tricky balance. We use propensity weighting to adjust for feature regions with imbalanced treatment assignments. But if the region is too imbalanced, the inverse propensity is not effective anymore. In short, it is very easy to overfit on some rare examples.
Transformed outcome needs Inverse Propensity Weighting
There is a second reason to use inverse propensity weighting. Recall the transformed outcome formula. In it we assumed P(W⩵1)⩵0.5, resulting in our labels -2, 0, 2. Thus we assumed there is an equal number of treated and non-treated customers. It also assumes that the selected users come from the same distribution.
The easiest way to meet these assumptions in the dataset is by having random experiments. Yet, this is a bad idea because we want to be able to use both historic data, and the data gathered by our model. Note that this was the first option we listed when dealing with the treatment bias.
Or, we could use a different value for p in the formula, based on the treatment frequency. But there is a causal link between features and treatment assignment. That treatment propensity thus differs per region in the feature space. A different p value would fix the global imbalance, but we would still have the local treatment bias. This would thus demand us to change the p value, and thus also the label, per feature space region.
So we need the local treatment propensity (the local p value). Either we transform the label, or we apply inverse propensity weighting. The latter results in a uniform distribution of weighted treatment assignments. For every part of the feature space. Meanwhile, we also balance the number of weighted treated persons in total. The inverse propensity weighting solved our treatment assignment bias. And while doing so, it also allows us to use P(W⩵1)⩵0.5 for all samples.
Third issue: following your model’s predictions
By tackling the previous two issues, we’ve constructed a reinforcement learning setup. There we covered getting quality predictions on which we can act. The last issue we need to tackle is getting good feedback.
Exploiting the best-predicted treatment gives us some feedback. It will tell us the effect of the treatments the model currently thinks are best. But it will not tell us anything about alternative treatments, because we don’t execute them. The model creates its own blind spots. Thus we need to balance exploitation with exploration.
Balancing exploration and exploitation
We need to balance exploration and exploration in two dimensions. First, we need to execute alternative treatments for certain users. The business often has constraints restricting the number of customers they can treat. For example, allocated budget or resources. We, on one hand, need to know the treatment assigned to each customer. But we also need to choose, with some exploration, the customers to treat.
Selecting a treatment for each customer
Thompson sampling is a powerful technique for assigning treatments to customers. Up till now, we regarded the predicted uplifts as point values. They are the most likely uplift of an underlying distribution. And Bayesian modeling can model those underlying distributions. We then don’t use the most most likely value of each distribution. Instead, we draw a prediction from each distribution. On average it will be equal to the most likely value. But in this way, we pass on prediction uncertainty into uncertain actions. Thus, we combine the sampled prediction with customer lifetime value and treatment cost. That then defines the best treatment for the customer.
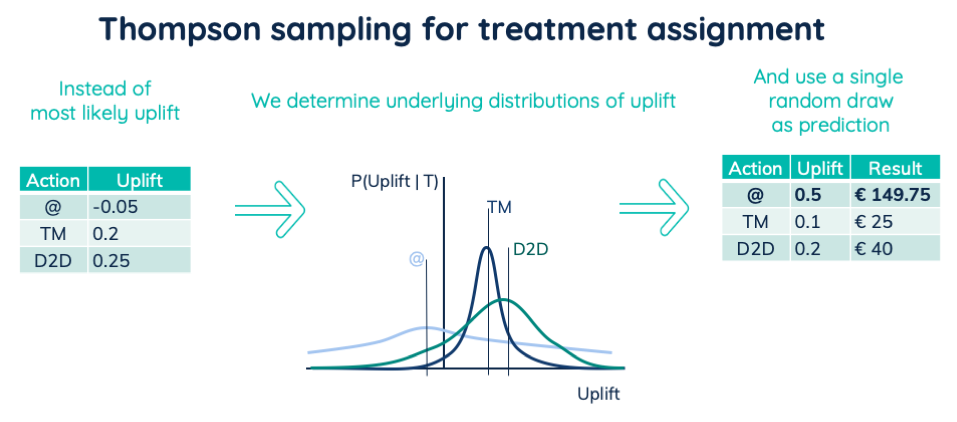
Overview of Thompson sampling
In this way, we will, in general, apply the best treatment. Where we sometimes apply a potentially better treatment. Thus we explore the treatments that have the most potential. And the model uncertainty defines that potential. The higher the potential the more often we will apply it. Those actions resulted in new information. That information then lowers our model uncertainty right where we need it. Allowing us to find potentially better treatments.
Selecting customers to treat
Knowing the best treatment, we could apply the best treatment. Yet, the sum of costs might be higher than your budget, or it takes too much time to execute. Under those restrictions, we want to maximize the total reward. So we can sort all our customers decreasingly by net reward. Then we go down that list treating the customers until we either reach reward zero or our time/budget ran out.
But those customers will originate from a certain area in the feature space. The other areas become our blind spots. Those blind spots prevent us from learning the treatment effect of those customers. Thus we also need to explore across customers.
One way is to randomly select customers to treat. Where the probability of accepting someone is proportional to the net reward. If someone has twice the net result, we include that person twice as likely. From this group, any random selection will balance exploration and exploitation. Unfortunately, it has a big issue. We are ignoring the uncertainty. If we are 100% certain that one customer has a low (or negative) net reward, why should we include it sometimes? Further, this approach is tricky to calibrate. It is difficult to get a selected group of size equal to the number of customers we can treat.
An alternative way is to perturb some results. We take a small percentage, like 5%, out of our predicted list. We then replace their net result with a value randomly drawn from all our predictions. In this way, the distribution of predictions remains the same. And we are randomizing 5% of our treatments. The advantage of this approach is that any top-N selection will have 5% random samples. With the first version of our model, we can start with a higher percentage like 10%. The more certain we are about the prediction quality, the lower we can bring the exploration rate. Keeping the exploration rate non zero will ensure a decent diversified dataset. This allows our model to retrain better in the future.
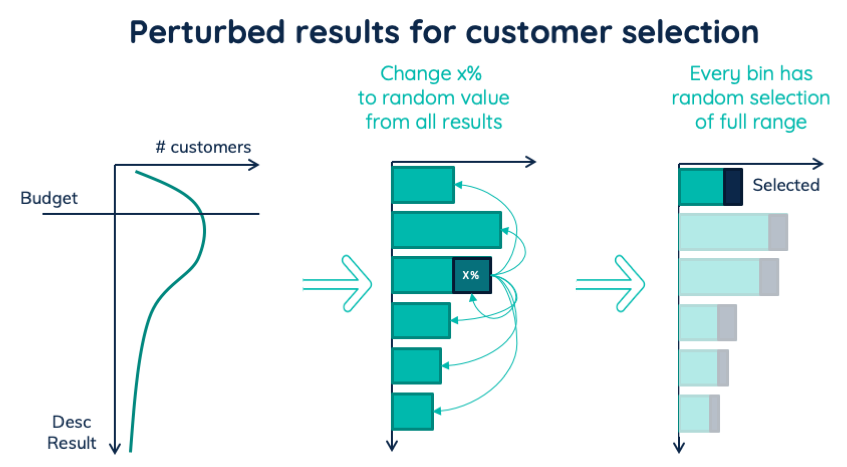
Overview of perturbed results, used to include random group of treated customers.
Uplift modelling meets causal inference in a bootstrapped reinforcement learning setup
We now have covered three essential techniques to prevent churn. We created a reinforcement learning setup that will continuously learn and improve. Available historic data bootstrapped its training. The core is a regression model predicting uplift. For each treatment, we estimated the net business result. That calculation combined the uplift, customer lifetime value, and the treatment costs. But previous and existing treatment policies will create a biased model. Thus we also created a propensity model, predicting the treatment assignment (the bias). Inverse propensity weighting was the solution. It used the treatment propensity values to determine sample weights. Our core uplift regression model then trained using these sample weights. In that way, we ensure our regression model isn’t biased.
To keep improving our model, we need to be able to retrain it using feedback on applied treatments. So we made our uplift regression model Bayesian. This allowed us to apply Thompson sampling to predict probabilistic uplifts. In this way, we explore the treatment assignment. We also explored the customers to treat. We implemented this by first selecting a small percentage of the customers. Then we assigned a random treatment result to them. This way has two advantages. Independent of the number of customers the business finally treat, we always treat a small random group. Also, we don’t have to update business processes when we change exploration rates. The better our model is, the lower we decrease this exploration rate. Note that the random group still gets its best treatments. This then creates exploration across customers.
Putting it all together results in the following setup:
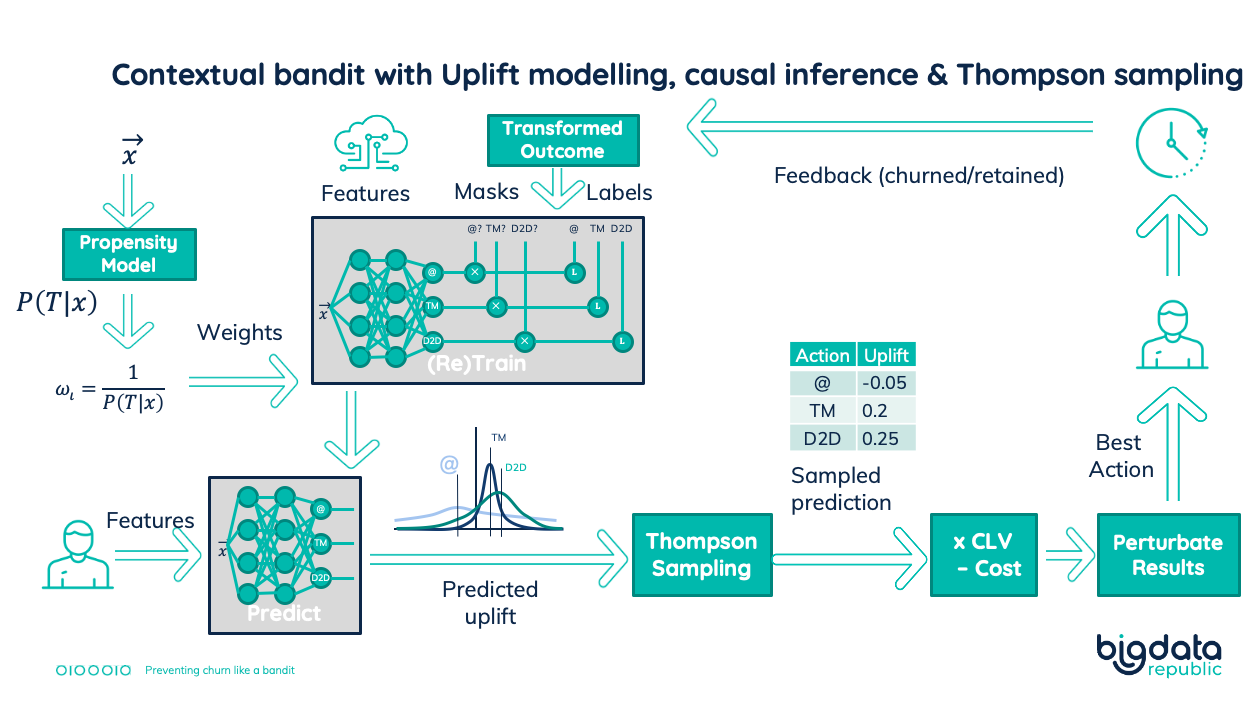
Complete setup to prevent churn. Combining uplift modeling, causal inference, and bootstrapped reinforcement learning.
Combining schools of thought
This setup has brought together methods from different lines of thought. We focus on feedback and actionable (prescriptive) predictions from a reinforcement learning perspective. We take into account bias and causality using inverse propensity weighting. We take into account uncertainty and the balance between exploration and exploitation. Finally, we focused on the improvement of our action using uplift modeling. We thus brought together uplift modeling, causal inference, and reinforcement learning.
I hope that these techniques are of use to your machine learning application. Let’s escape from models that predict what happens. Let’s start to improve business processes.
Further reading
This blog-post elaborates on the churn vs uplift prediction.
This blog-post has a more thorough explanation of causality and causal diagrams.
For a great introduction of uplift modelling checkout the documentation of python package pylift. The original paper is:
The following articles have more information about inverse propensity weighting:
- ‘Propensity score weighting for causal inference with multiple treatments (Fan Li, and Fan Li, 2019)
- Efficient Estimation of Average Treatment Effects Using the Estimated Propensity Score (Keisuke Hirano, Guido W. Imbens, Geert Ridder, 2000)
- Estimation of Causal Effects using Propensity Score Weighting: An Application to Data on Right Heart Catheterization (Keisuke Hirano, Guido W. Imbens, 2001).
- The central role of the propensity score in observational studies for causal effects (Paul R. Rosenbaum, and Donald B Rubin, 1983)