Dealing with abrupt market changes in your analysis - a brief tutorial on time series change point detection
The Covid-19 crisis has an extraordinary effect on global economic activity. After this crisis it will remain important to take this period into account when training machine learning models on historic data. An important step is to identify when your industry started to get affected by the crisis and — once the crisis is over — when it returns to a new normal. This problem is called time series change point detection. In this blog we will cover two approaches to detect abrupt change points: piecewise linear regression (PLR), and hidden Markov models (HMM).
For illustrative purposes we will apply change point detection to a single stock value time series (SPYD) showing a large drop when the Covid-19 crisis started.
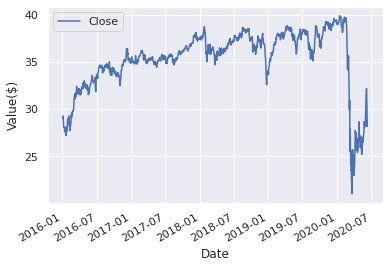
Stock value time series (SPYD)
In practice you would apply these methods to one or more time series of your sales volume over time or economic activity in your industry and region of interest. Although the fall in revenue may not be instantaneous, an abrupt deviation from the previous trend is typically observed. Especially when analyzing data from multiple regions with different lockdown measures in place, a simple analysis to quantify the start and end of the Covid-19 impact is useful. To repeat and experiment with the analyses discussed in this blog check out this Jupyter notebook.
Piecewise linear regression
The idea behind piecewise linear regression (PLR) is as follows: instead of minimizing the mean squared error as in linear regression, we minimize the mean squared error of several connected lines. This is a difficult problem, since the switch from one line to another connected line can happen anywhere. It is possible to fit a time series perfectly by drawing a new line between each pair of consecutive points. To prevent overfitting, it is important to limit the number of lines to be used. Fitting only one line — that is assuming no change points — is equivalent to standard linear regression.
The aim of our analysis is to identify distinct time periods: for example a pre-crisis and crisis period. It makes sense to set the number of lines to two during the crisis, and to three once a clear post-crisis period has emerged. Below we see the fitted lines of PLR with two lines. In this particular case the crisis period seems to consist of a significant drop followed by a relatively strong upswing. This suggests that fitting three trend lines instead of two provides a better fit.
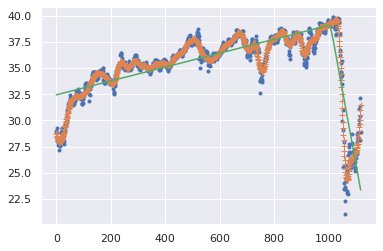
Fit of piecewise linear regression (green) on a smoothened version (orange) of the stock value time series (blue)
The connection of the two green lines of the PLR can be used to identify when one period transitions into another. The slope of the lines indicates how much the metric or index has changed on average during the different periods.
The advantage of PLR is that it is conceptually simple and that it identifies abrupt transition points as well as the rate of change within each period. An important disadvantage is that without a ground truth, choosing the number of lines is somewhat arbitrary. It is therefore important to verify that the solution makes sense.
Hidden Markov Models
An alternative approach to change point detection is using continuous hidden Markov models. A continuous HMM is a probabilistic model. It assumes that its unobserved states are qualitatively distinct. In our case these states are two periods: ‘pre-crisis’ and ‘crisis’. It also assumes that within each state the modeled data points come from a normal distribution with fixed mean and variance. The latter assumption is often not realistic, but as we will see can still result in sensible outcomes.
In general HMMs assume that transitions can happen at any point in time and move back and forth with a certain probability. Note that staying in the same state is also considered a transition in an HMM. Taking time into account leaves us with three possible transitions:
- Remain in pre-crisis
- Move from pre-crisis to crisis
- Remain in crisis
Of these transitions the move from pre-crisis to crisis only happens once. This is the transition identifying our changepoint of interest. To model time we fix the reverse transition probability from crisis to pre-crisis to zero in the so-called transition matrix and initialize all others to 50%. During training the HMM fitting algorithm will estimate all non-zero transitions. In addition a mean and variance for each of the two states will be estimated.
To match the assumptions of continuous HMMs better, we first detrend the time series. That is, we don’t model the time series values themselves, but model the difference between consecutive time points. This means that our HMM will be based on the assumption that within each period the mean change per time point is constant with stable variance. This is analogous to the linear assumptions we made in our piecewise linear regression approach. Below we show two plots:
- The detrended time series on which the HMM was trained.
- The periods on the original time series identified by the HMM assuming two distinct time periods or states.
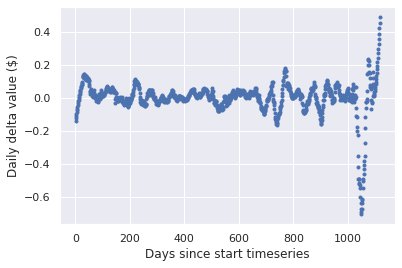
Daily delta value of the original SPYD stock time series
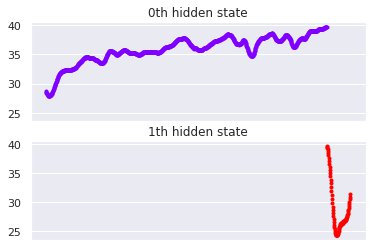
Two qualitatively different periods identified by the HMM
The different colors indicate the identified periods. We can therefore use the transition between periods as the detected change point.
Because of their probabilistic nature, HMMs can result in different solutions when fitted multiple times, or worse, not converge at all. These are warning signs that the model assumptions do not match the observed data well. It can sometimes help to smoothen a time series before fitting it to dampen the effect of large outliers.
Changing the number of states can also help, but unlike piecewise linear regression, continuous HMMs sometimes simply cannot fit a particular time series robustly. This can show in different ways:
- When you train the HMM multiple times on the same dataset you get very different solutions.
- You get solutions with a extremely large variance indicating the model could not converge.
- One or more identified periods are too short to be meaningful.
Although such stability issues are inconvenient, they signal that there is not a single unambiguous HMM model that matches the data. Note that being able to fit any time series as PLR does is not necessarily a good thing, since it does not discriminate situations in which the fit makes sense and when it does not.
Using change points in practice
We have discussed two unsupervised methods to identify the abrupt changes in a time series, such as the start and the end of the Covid-19 crisis. We can use this information in two ways. The easiest and safest option is to completely ignore the crisis period during model training of future models. The rationale would be that this period is not representative and therefore uninformative for daily business decision making after the crisis. The main disadvantage is that this disqualifies large amounts of potentially informative data.
The second option is to try to control for the changing market conditions. Depending on the exact model setup, the identified periods can be included as model features and taken into account during training and cross-validation. Although it is likely that some bias will remain, robust field testing of the trained model can provide insights in how big that problem is.
Whichever method you choose to identify the start and end of the Covid-19 crisis for your industry, controlling for this extraordinary period is essential as it will affect the conclusions of future data analyses long after the crisis has ended. If this blog has whetted your appetite for more advanced change point detection methods make sure you have a look at this post as well.