The essentials of an MLOps platform Part 1: Architecture
When building Machine Learning products, an important aspect is getting the foundation right. You'll need a scalable and solid architecture where these products can be easily deployed and maintained. But what are the essentials of such an MLOps architecture?

The main motivation of writing this blog is that we experience that companies do not always have a clear view on the machine learning lifecycle and the relevant tooling. We want to showcase a concrete example architecture to inspire clients and / or MLOps engineers. This architecture should be cloud agnostic and contains building blocks ranging from model development to its serving with only a single method for user authentication (Oauth).
Cloud infrastructure
Let’s start with the setup of a basic cloud infrastructure. In the example below we use Google Cloud Platform (GCP), but it is applicable to every cloud provider.
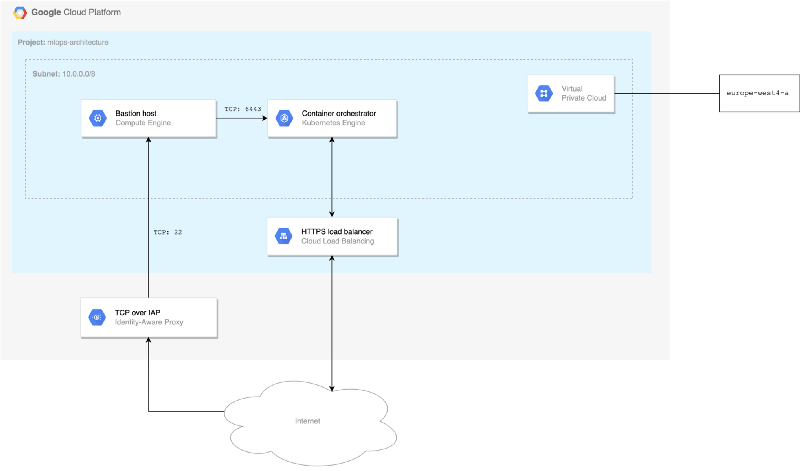
Basic setup cloud infrastructure
First, a virtual private cloud (VPC) is created. This is a secure network hosted within a public cloud. VPC customers can run code, store data, host websites, and do anything else they could do in an ordinary public cloud.
Secondly, we use Identity-Aware Proxy (IAP) to access the VPC. It provides you control over which users are allowed to establish tunnels and which VM instances in the VPC they can approach. In addition, we enable a bastion host to access the VM instances that do not have external IP addresses or do not permit direct access over the internet. This host provisions which VMs in your private network act as trusted relays for inbound connections.
Finally, external HTTP(S) Load Balancing is added to run and scale your services behind a single external IP address. External HTTP(S) Load Balancing distributes HTTP and HTTPS traffic to backends hosted on a variety of components. For instance, in the example above we highlighted the component Google Kubernetes Engine (GKE) as an illustration.
MLOps architecture
With the cloud infrastructure set up, we can start building the MLOps architecture. Using the diagram below, we guide you step-by-step across the different building blocks.
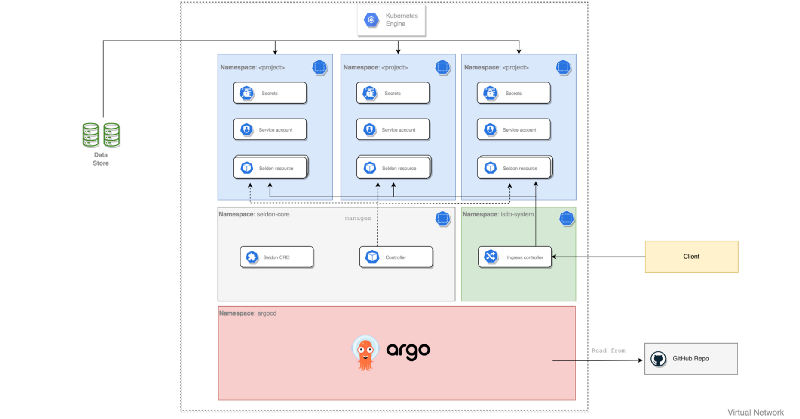
Different building blocks of basic MLOps architecture
ArgoCD
As a foundation of an MLOps architecture you might want to consider a component that manages and rolls-out all deployments in your environments automatically. Our preference would be to use ArgoCD for this purpose (bottom component in the visual). ArgoCD is a declarative GitOps tool built to deploy applications to Kubernetes and does not have the UI overhead of many tools built to deploy to multiple locations. Moreover, ArgoCD automates the deployment of the desired application states in the specified target environments. Application deployments can track updates to branches, tags, or pinned to a specific version of manifests at a Git commit.
Application deployments
As described above, ArgoCD can deploy applications. An example can be found in the grey using the architectural image above. Here Seldon Core is an application and can be deployed using a Helm Chart, which defines a package of pre-configured resources. ArgoCD automatically synchronises environment configurations in the Helm Charts and deploys them accordingly to a Kubernetes cluster using your CD pipeline.
Project namespaces
On top of that, you can see in blue a single cluster that should be able to satisfy the needs of multiple users or groups of users. These Kubernetes namespaces help different projects, teams, or customers to share a Kubernetes cluster. However, within a company, user groups want to be able to work in isolation from others. The namespace provides a unique scope for:
- Authentication (who are trusted users)
- Resources (pods, services, enabled application components, etc.)
- Policies (who can or cannot perform actions within their group)
- Constraints (this group is allowed this much quota, etc.)
- Network restrictions (which pods can talk to each other)
Use cases include:
1. Support multiple user groups on a single cluster.
2. Delegate authority to partitions of the cluster to trusted users in those groups.
3. Limit the amount of resources each group can consume in order to limit the impact on other groups using the cluster.
4. Interact with resources that are relevant to my user group in isolation of what other user groups are doing on the cluster.
Ingressor
Finally, we also need to have a component that handles the incoming traffic for your cluster and to not expose the entire cluster to the outside world. As you can see in the architectural image we chose Istio Ingress (green block), which is a subset of Istio to take on this responsibility. It exposes just the part of the cluster that handles the incoming traffic and routes that traffic to the applications inside. Moreover, it allows you to add additional routing rules based on routes, headers, IP addresses, and more. This flexibility in routing gives you the opportunity to implement concepts such as A/B testing, IP black/whitelisting, and so on.
MLOps components
In the previous section we described how Seldon Core can be deployed as application to our Kubernetes cluster. In addition to Seldon Core, there are other component that are required to satisfy the need of the users of our MLOps platform.
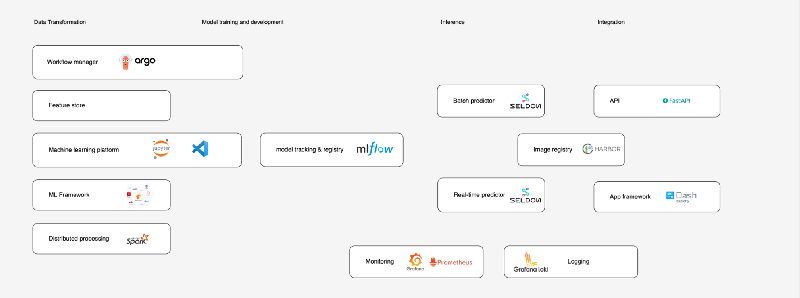
User components of MLOps platform
The MLOps components shown above are carefully picked based on their wide applicability and interoperability. Hence, the components serve as inspiration and could be exchanged with other components that suit your use-case. In the next section we highlight three of them.
Model tracking and registry
One of the main goals of an MLOps platform is to develop end-to-end machine learning models. MLflow is an open source platform for managing machine learning workflows. The MLflow Tracking component is an API and UI for logging parameters, code versions, metrics, and output files when running your machine learning code and for later visualizing the results. The MLflow Model Registry component is a centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of an MLflow Model.
Model deployment and serving
To leverage our trained machine learning models, we want to serve them, either in batch or real-time. Our proposed tool for this is Seldon Core which converts our ML models into production ready REST/gRPC microservices. Using Seldon’s Model Servers, models are wrapped into pre-made containers and are immediately reachable due to clever routing. With a trained MLflow model you are able to deploy one (or several) of the versions saved using Seldon’s prepackaged MLflow server. The prepackaged MLflow server is uploaded as a Docker Image to the Image Registry. Seldon Deployment CRD allows you to easily deploy your inference model to the Kubernetes cluster and handle prediction requests. Seldon Core supports batch inference out-of-the-box which speeds up performance compared to looping over single predictions.
Monitoring
An important aspect of any platform is monitoring the status of applications, resource usage and incoming traffic. To capture and visualise metrics, we propose Prometheus and Grafana. Prometheus is a monitoring solution for storing time series data like metrics. Grafana allows to visualise the data stored in Prometheus (and other sources).
Besides raw metrics, Grafana’s log aggregation and storage system Grafana Loki allows you to bring together logs from all your applications and infrastructure in a single place.
We hope you find this blog post helpful and can be used as reference for building your own MLOps platform. Moreover, we are planning to write additional blogs with details on the usage of ArgoCD and setting up the basic infrastructure for the MLOps platform. Keep posted at our Resources page.