Secure machine learning APIs with Seldon and BentoML

I’ve been in the machine learning industry for over five years, and although many interesting developments have been made over the years, one thing keeps getting neglected: security. It actually baffles me how a discipline within IT that deals with sensitive — and often personal — data cares so little for cybersecurity. My current client is a breath of fresh air in this regard. In my role as tech lead I have the mandate to steer my team towards solutions that put security and privacy first. We’ve successfully deployed BentoML and Seldon to our cluster to securely serve model APIs. In this blog I’ll touch upon the security advantages of using these frameworks.
The last couple of months, my team has worked on deploying (and contributing to!) Kubeflow to make sure our data scientists can securely process data on an air-gapped cluster. Before we built this platform, data scientists had to download data to their local (albeit encrypted) laptop. We are now successfully running production with our platform and serve over 100 of our organization’s data scientists.
To take things to the next level, my team is now working on a solution for securely serving machine learning models across the organization. Specifically we productionize models using REST and gRPC APIs, integrating them with business software and existing processes. To select tools that could help us facilitate this, we started by listing a set of requirements:
Ease of use
It should be as easy as possible for a data scientist to expose their machine learning models as an API. Data scientists in this organization don’t always have engineering skills or experience with securing APIs, so the tool should steer them towards the “correct” solution as much as possible.
Single sign-on
The APIs should be called with an OIDC token from our identity provider to authenticate the user calling the API. In the event of a system calling the API instead of a human, we allow a service account. We want to facilitate authentication as a platform feature, so the data scientist deploying the models doesn’t have to worry about it.
Authorizations
Data scientists should be able to decide who can access their machine learning model. They often have a better idea of the authorization requirements than we have as a platform team.
Auditing
We should be able to monitor and audit all requests that pass through the machine learning model APIs.
BentoML
BentoML is a framework for building and packaging machine learning APIs. When building APIs, many data scientists just pip install flask, don’t bother with authentication, use the Flask development server and wham, “we’re running production”. BentoML tackles a lot of these issues:
- It forces you to apply some kind of structure to your APIs, and subsequently exposes a Swagger UI for your API.
- It enables you to easily package your model into a Docker container.
- You can use it to version your machine learning models.
- It uses the highly optimized Gunicorn to serve your application, which is much more performant than the single-threaded Flask development server.
The API is quite simple and supports many of the popular machine learning frameworks like scikit-learn and TensorFlow:
The nice thing about Bento compared to other model serving frameworks is that it augments your existing code instead of replacing it. You can keep your existing training and prediction functions and use decorators to specify e.g. the artifact and Docker base image to use. The code sample above generates a directory that contains a Dockerfile, a requirements.txt and the code necessary to train and use your model. Building the Dockerfile leaves you with an image that contains everything needed to deploy the image on a Kubernetes cluster with e.g. Seldon.
Seldon
Seldon Core is a project that allows you to easily deploy machine learning models to a Kubernetes cluster. We opted for Seldon because of its support for Istio, the service mesh that we are already using to manage authentication, authorization, encryption and monitoring on our platform.
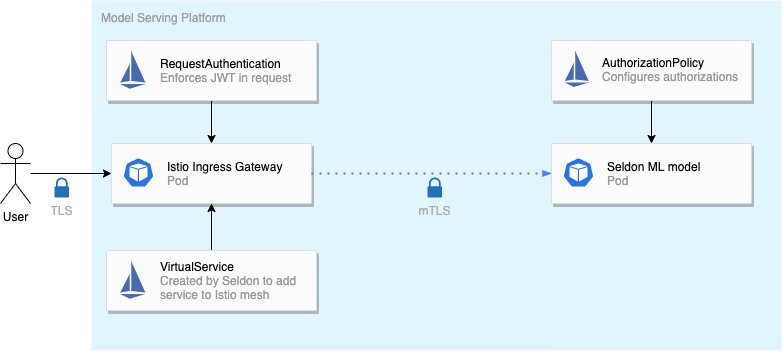
Overview of traffic to Seldon
To deploy a Seldon application we create a SeldonDeployment resource:
The componentSpecs field allows you to specify the same spec as for a regular Deployment resource. The graph field specifies the Inference Graph, which can include preprocessing or postprocessing steps. For now, the graph is very simple and just routes all requests through the bentoml-example:latest container.
Because we run a multi-tenant cluster, we create namespaces per project to which only the respective data scientists have access. Data scientists have full access to create resources in this namespace, such as the SeldonDeployment shown above, but also additional services such as a database or additional models for A/B testing.
Using Istio to secure the API
In the default configuration, Seldon doesn’t make your APIs more secure. This requires additional setup by the platform administrators. However, once setup, data scientists can deploy APIs without having to worry too much about security.
To enable support for Istio, we apply the following environment variables in the Seldon controller:
Once Istio support is enabled, Seldon will automatically create the correct VirtualService resources for both HTTP and gRPC ports, and will apply the necessary mTLS configuration.
TLS
When you enable Istio support in Seldon, all traffic to and from your machine learning models is automatically secured using mTLS. On a multi-tenant cluster, this is important to prevent eavesdropping. For exposing the service outside of the cluster, TLS is added at the ingress gateway, based on Envoy.
Authentication
Because our machine learning API is now exposed through Istio, we can add a RequestAuthentication resource to enforce a JWT being present on all incoming requests:
Now, all requests that pass through the api namespace (where our ingress gateway is located) are required to have a valid JWT. Without a valid JWT, the request is rejected with a 401 HTTP error.
It is the responsibility of the client application to go through the proper OIDC flow to obtain a token.
Authorization
We want the owner of the data science model to be able to choose which teams or users should have access to the data science model. We can do this by allowing data scientists to create Istio’s AuthorizationPolicy resources on their namespaces:
So by enabling Istio support in Seldon, we have automatic encryption of traffic within the cluster, enforce authentication of clients for all models, and give data scientists the ability to add authorizations independently. Because all requests pass through Istio, we can also monitor requests using Jaeger for tracing. With Seldon we can do even more awesome things like A/B testing, model explaining and outlier detection.
In conclusion, by using these tools we enable data scientists to deploy models with the correct security criteria, without requiring too much knowledge of concepts like mTLS and JWTs. This speeds up the process of productionization and increases security of our platform.