
A review of Netflix's Metaflow
tl;dr Metaflow is a framework that alleviates several infrastructure-related pains data scientists experience in their projects. It takes care of versioning, dependency management, and management of compute resources. If you use AWS, Metaflow can help you structure your data science projects from early development to production. For problems that it does not solve, other tools exist that do the job. If you are not using AWS, Metaflow is not that useful.
Recently, Netflix open-sourced Metaflow, their internal data science platform. The platform was built to reduce the time-to-market of data science initiatives at Netflix by tackling common pain points related to infrastructure and software engineering. Building a data product requires a broad set of skills. Data scientists generally do not possess all of these skills. The figure below visualizes this well. Data scientists want to focus more on solving business problems by building machine learning models, rather than setting up an excellent infrastructure to facilitate this process.

Figure 1: aspects of a data product
Metaflow takes away some of the burden of the infrastructure-heavy work from data scientists. As it is a platform, it does not solve a single problem. It serves as a generic framework to increase data scientists’ productivity during both experimentation and productionization.
In this article, I will briefly highlight the features of Metaflow. After, I will tell you my opinion on it, and when it is useful for you. At first sight, it reminded me of Apache Airflow. Therefore, I will compare the tools on some facets.
Note: I have not worked with Metaflow in a real-world scenario. The review is based solely on my first impressions of reading the Metaflow documentation and code.
Metaflow Features
Structure
Metaflow is a Python library, providing data scientists with a framework to structure their code as a directed acyclic graph (DAG). A Metaflow DAG is a Python class describing a number of steps of work that will be executed, and dependencies between them. Figure 2 shows an example of such a class. In this example, 5 steps are created. The steps separate data loading, model training, and evaluation. In each step, the next steps are referred using the self.next method. This creates a graph defining the order in which steps are executed.
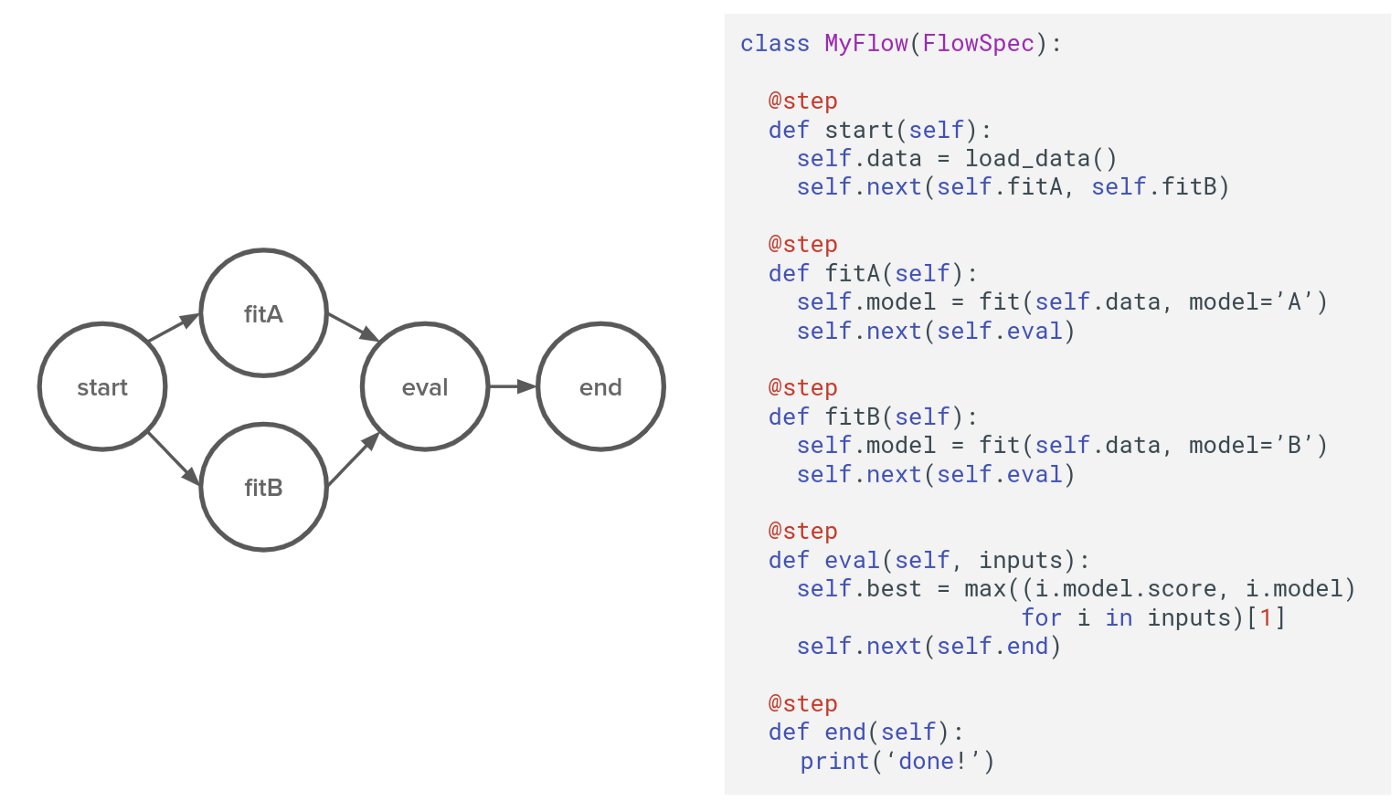
Figure 2: an example Metaflow DAG
Compute Resources
These steps can be run either locally or distributed using AWS Batch. This allows you to run the code in a production setting, while providing the option to test it locally on a single machine. Running these steps happens via the CLI shipped with the Python package.
Metaflow takes care of serializing, persisting, and de-serializing objects between steps. Take the above graph as example. In the start step, self.data gets filled with the loaded data. in the fitA step, self.data is then used to fit a model. When running this workload locally using a single Python interpreter, self.data is obviously available in both steps. When running on AWS Batch, multiple Python interpreters will be used on potentially multiple compute nodes. Metaflow handles the communication between steps for you by pickling objects that are passed to next steps, and storing them in S3. Metaflow also ships with an high-throughput S3 client, which is integrated with Metaflow’s versioning feature.
The serialized intermediate results of your DAG are part of the versioning functionality of Metaflow. Whenever the DAG is ran, the serialized objects are stored in a new, unique location. This is handled by the Metaflow library. Along with that, metadata is stored, providing information about a run. This metadata can be queried via the Metaflow Python client library.
In Metaflow you can use the @resources decorator to define the required resources of a step. These resources will then be provided by AWS Batch if they are available in the cluster. When running in local mode, the decorator will be ignored. This decorator provides a way of tweaking the resources per step. The decorator also allows you to request GPUs. In addition to the @resources decorator, Metaflow provides the parallel_mapfunction to do multi-core processing, similar to Python’s multiprocessing library. Splitting a step over multiple compute nodes is also possible, using Metaflow’s Foreach feature.
Error Handling
Errors are inevitable in distributed, data-intensive systems. Metaflow’s @retry decorator can be used to define retries on your steps. Exceptions can be caught using the @catch decorator. For long running jobs, the @timeout decorator can be used.
Dependency Management
Python projects often consist of an ensemble of various packages. Keeping these dependencies fixed among runs of your system is crucial for deterministic behavior. Metaflow provides the @conda decorator, which lets you specify the Python packages used in each step. Metaflow will create a Conda environment, and cache it in S3. To specify DAG-level depenencies, use the @conda_base decorator.
Many Python packages require non-Python dependencies. Think of compilers and database drivers. These dependencies are usually not available to Metaflow steps, as steps are executed in a vanilla Python docker image by default. When requiring non-Python dependencies, you can run your steps in a custom docker image.
The Review
Interface
Metaflow provides a clear interface for configuring your DAG. The use of the various decorators on the methods makes the code very readable. I like that most of the features can be easily configured this way.
State
Out of the box, Metaflow allows you to pass variables across steps. I like their decision of abstracting away (de-)serialization using Pickle and S3, as this works fine for most use cases in Python-based machine learning workflows. By abstracting this away, Metaflow can decide to serialize state in different ways, i.e. when running in local mode. This makes testing your workflow a lot easier. If the serialization does not work for you for some edge case, you can always choose to explicitly serialize your state. Be aware though that you keep your package and Python versions constant across steps, as Pickle does not work well across versions.
The state sharing is different from e.g. Airflow, where every step generally starts and ends with data at rest in a data store. Airflow does offer state sharing through XComs, but requires you to explicitly send and retrieve the state in your steps. An alternative to XCom in Airflow is to use the output of the previous step as input of your next step. If you wish to do pass state between steps in Airflow, you have to think about (de-)serialization yourself. Because of this, Airflow comes with various components that handle interaction with many popular external systems for you. This provides quicker integration with data stores other than S3, but adds more complexity to your DAG as well. This difference between Airflow and Metaflow stems from their design goals. Airflow has a strong focus on ETL pipelines, whereas Metaflow is built for Python-based machine learning workflows.
Cloud Environment
The most important features of Metaflow are tightly coupled to AWS. Without S3 and AWS Batch, the tool is not really useful. This is a pity. Luckily, Metaflow is an open-source project, so it is possible to add non-AWS alternatives later. AWS-specific components are mostly isolated into separate modules, and inherit from abstract base classes describing their interface. This should make extensions to other backends reasonable.
Missing Features
Metaflow does not solve all problems of data science projects. It does not need to, as there exist other tools that can complement Metaflow. It does not come with a job scheduler. This is fine, as there are enough AWS-based (Step Functions) and open-source alternatives (Airflow) out there.
Metaflow does not help you serve your models in production, using a REST API or Kafka consumer for example. Again, this problem is tackled by open-source (Seldon) and AWS based (Sagemaker) tools.
Scalability
I like that Metaflow provides various features for scaling your workflows up or out. The @resources context manager allows you to select very large machines to run your jobs, and parallel_map provides a single-function alternative to Python’s multiprocessing library. Netflix claims that it is even an improvement over multiprocessing. With these tools, you can scale vertically until it is no longer an option. Code for horizontally scaling is often more complex than for vertical scaling, so these features are very helpful.
For the cases where horizontal scaling is useful, Metaflow provides you with a straight-forward way of achieving this in your steps. Under the hood, AWS Batch spawns a container on ECS for every Metaflow step ran. If individual steps take long enough, the scaling should outweigh the overhead of spawning these containers.
You cannot specify the type of GPU requested with the @resources context manager. AWS offers various types of GPUs, and they can be added to your AWS Batch cluster, but selecting the GPU you would like to use for your machine learning model is not possible in Metaflow. As the choice depends on the model architecture being trained, it would be a good feature to be able to specify this.
Dependency Management
You can easily define your Python dependencies per step, or for your complete DAG. Fixing the versions is possible too, which is also crucial for deterministic execution of your system.
Local packages get packaged with your DAG code for remote execution, and get added to the path. This makes it easy for your DAG to reference the code executed by the various steps. This is nice, as it allows you to develop your code as a Python package, which you do not need to somehow install on your remote hosts or in a Docker file. Developing it as a Python package makes imports and testing very easy.
The option to provide your own Docker container to run your steps in greatly increases the flexibility of the product. By using this, you should be able to handle most data science project dependencies.
Lock-in
With every tool, it is interesting to analyze how easy we can get rid of it in case we are not happy. The Metaflow code does not get mingled with the rest of our codebase. It merely functions as a “main script” that calls the code needed for each step. If we want to replace Metaflow later, we just have to change this file, and the features provided inside of it. Because dependencies are managed using Conda and Docker, we can lift-and-shift them to a different system as well.
Most Metaflow features can be added to a step using decorators. Metaflow provides base classes for step- and DAG-level decorators. This allows you to build your own decorators that add custom logic. This extensibility greatly reduces the lock-in of the product. Currently, no community-maintained plugins exist yet.
The Verdict
All in all, I think Metaflow is a neat tool. If your data scientists struggle a lot on the infrastructure part of their projects, Metaflow can streamline this process. Metaflow, in combination with other tools for scheduling, deployment, and serving, looks like a great data science stack. But before adopting it, you should do some proper testing on real AWS infrastructure, of course. Unfortunately, for now, if you are not on AWS, this tool is useless to you. Feel free to implement the features for other cloud providers as well though!