Integrating Pandas and scikit-learn with Pipelines
Scikit-learn and Pandas are both great tools for explorative data science. Both require a bit of practice to get the hang of. The phrase “Hey Alex, how do I achieve the following in Pandas?”, is often heard in our office. Everyone at BigData Republic — no exceptions — is familiar to some degree with Python and Pandas. Nearly all products start off as a clutter of Pandas operations before gradually maturing into a production-ready code base.
Framing the problem
Although scikit-learn accepts Pandas dataframes as input, it strips the tables of everything that makes Pandas wonderful and instead returns regular ol’ Numpy ndarrays with the risk of confusing columns and no longer knowing what's what. This is usually not a problem for small datasets, however we often encounter large datasets with many kinds of data types that require different treatment. In practice, this means glueing Transformers together, losing intermediate types and risking errors. In this blog tutorial I'll show how a few custom transformers enable pipelines to handle multiple data types including categoricals, while still having the bookkeeping capabilities of Pandas for handling complex datasets. If you don't know what Pipeline or Transformer are, I recommend you read about those first.
tldr: wrap every operation in a Transformer class to enable Pandas and keep your modelling simple.
The final pipeline
We’ll start off with the end in mind. We would like to build a pipeline that supports multiple kinds of datatypes, including both numerical and categorical data. The end result should fit neatly into a classification or regression model, whether it be scikit-learn, Keras or statsmodels.
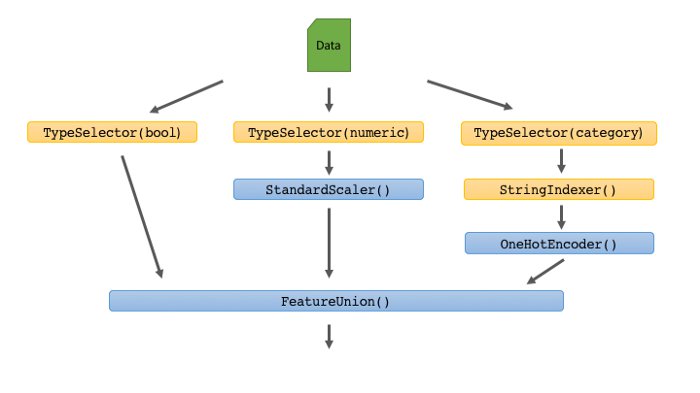
Example pipeline
Every blue segment is a standard scikit-learn Transformer. The yellow segments are custom-made. We'll discuss the components one by one. The code below is the same pipeline, now expressed as a scikit-learn Pipeline estimator object.
In the rest of this blog post we’ll go over the pipeline components one by one.
The new transformers we introduce are the TypeSelector and the StringIndexer.
Part 1: TypeSelector — combining multiple data types
Scikit-learn has a transformer for combining multiple feature spaces, called FeatureUnion. It’s essentially a horizontal concatenation of multiple separately processed feature tables. See the last segment in the figure above. This is a great starting point for processing different variable types separately; certain numerical variables need different treatment while categoricals are a different breed altogether. The first step is splitting a dataset into subsets of features that are closely related. One way of doing so is by making use of Pandas’ built-in data type selection, by using DataFrame.select_dtypes().
Putting it together
It’s nearly trivial to now write a Transformer that does the column selection for us.
The good part: the result of this transformer is still a dataframe, meaning we can chain more complicated transformers. This covers the first part of our pipeline.
Part 2: StringIndexer — Encoding of categoricals
Categoricals are not accepted by most machine learning models and require further encoding or creating dummy variables first. Luckily, Pandas can do most of the work for us. We will use the recently introduced Categorical data type. This type is similar to R’s factor. You can read more about it here.
We can transform an existing column into a categorical as follows.
It’s also possible to modify existing category columns by adding or removing values from the code book. See the manual. Under the hood, Pandas has already encoded the column as a list of low byte integers. In fact: it is nearly always cheaper — memory wise — to encode string or object columns as Categorical, often achieving compression rates up to ten times. We can inspect the codes and the categories through the Series.cat attribute.
Pandas does not explicitly include missing values in the code book and replaces them with -1 by default. If we want to include missing values as a separate category, we need to apply a small fix as OneHotEncoder expects values to be positive. The result is the following surprisingly simple indexer.
This indexer is built using .apply(), which can be incredibly slow and inefficient if used carelessly. For small datasets this should not be a problem, however a different — and less concise — Pandas call is required for production grade code.
In this example we treat all categoricals as nominal, meaning we also have to create dummy variables for following models to understand the features and their relationships. This dummy-creation process only works if the number of categories per variable is not too high. Scikit-learn’s OneHotEncoder is meant specifically for this purpose, encoding every category as a separate binary column.
Conclusion
I’ve shown that pipeline definitions become simpler by wrapping simple Pandas calls in Transformer objects. Specifically, I’ve shown that it’s easy to select columns based on data type (TypeSelector) and convert categoricals into numbers for further modelling (StringIndexer). There are a few catches. This setup requires discipline in your Pandas bookkeeping. Often there will be a holdout set for training and testing. For all of these sets, one should ensure that:
- the columns have the same types,
- the categorical columns require the same categories.Both are easily achieved by having a data ingestion process prior to the pipeline that makes sure the date is put in the correct format. This also holds for production environments where new and unseen data flows in.
P.S. for those interested, BigData Republic has a GitHub repository in which many of these classes and snippets are included. You can find bdr-analytics-py here.