
From predictive to prescriptive analytics - the benefit of causal diagrams
Suppose you work at as a data scientist at a dating site. Recently more and more customers are closing their accounts (a.k.a. churning). You want to understand which customers are likely to close their account. The strongest predictor for churning turns out to be whether or not someone searched how to close their account. Although you are excited about this predictive feature, what should you do with this insight? Although contacting customers that have searched how to close their account is an option, it is probably much more effective to predict which action would prevent these customers to want to churn in the first place.
This example illustrates the core distinction between predictive and prescriptive analytics. In predictive analytics the goal is to predict an outcome of interest, such as the churn probability per customer. In that case any predictive feature can be included in the model. In prescriptive analytics the goal is to identify an action that maximizes or minimizes an outcome of interest. For example, which of three user interfaces would minimize the churning risk for this customer?
This is part one of a series of two posts about causal inference, the art of estimating causal effects. In this first post you will learn how to use causal diagrams to make domain-specific causal assumptions explicit and how to use such diagrams to decide which variables need to be controlled for to get an unbiased estimate of your causal effect of interest. In part two you will learn several methods to actually estimate causal effects based on the relevant confounders identified by your causal diagram.
Before returning to our dating site example, let’s start with the basics of causal diagrams. In short causal diagrams are a tool to formally express assumptions about causal relationships between your variables of interest. More formally, causal diagrams are directed graphs in which nodes are all (domain) variables of interest, which may or may not be observed. The direction of the edges indicates the direction of causality between the variables of interest. We will focus here on directed acyclic graphs (DAGs) as this makes automatic reasoning about causal diagrams possible.
Below is a simple causal diagram reflecting some causal assumptions about the dating site example in the introduction. Light blue indicates unobserved variables, while dark variables are observed. Although this distinction is not part of the formal definition of causal graphs, it will prove useful later.
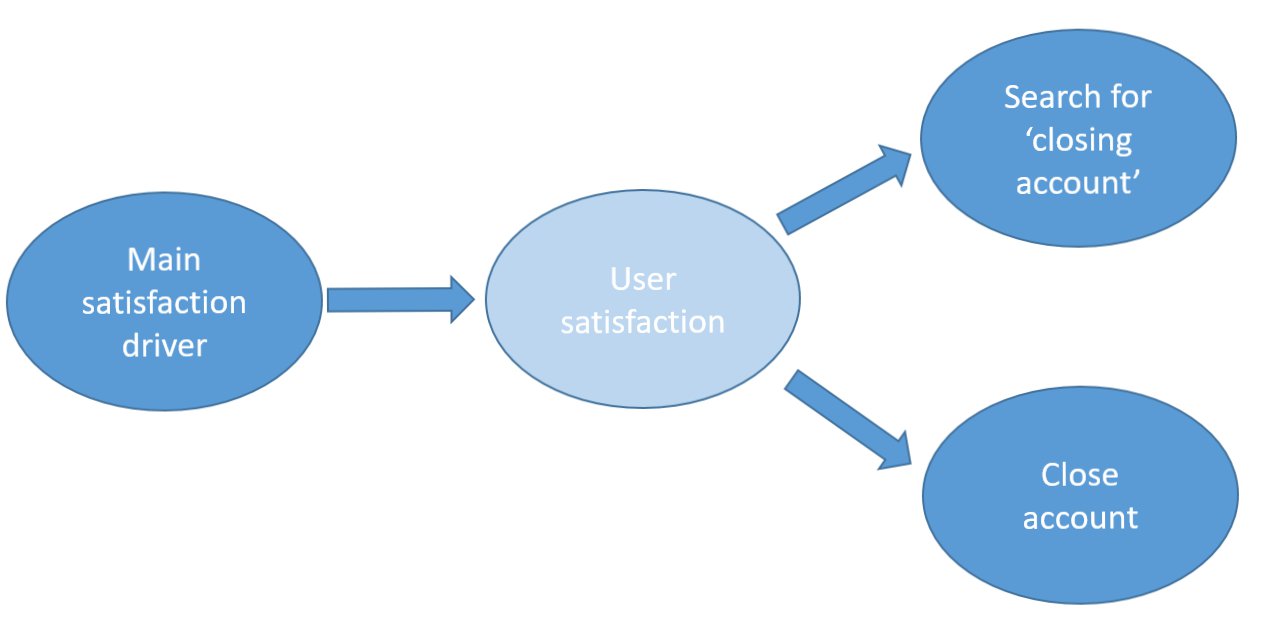
Figure 1. Causal diagram of churning
Although this causal diagram is self-explanatory, let’s break it down to its core assumptions. First, it expresses the assumption that user satisfaction independently causes both the search for how to close the account as well as the closing itself. The possibility that searching itself causes the closing of the account is excluded, as there is no additional arrow from search to closing. Second, user satisfaction is assumed to be an unobservable mental state that is caused by an observable causal factor. The diagram expresses the assumption that a single — yet unidentified — factor causes the unobserved user satisfaction.
If you find an alternative causal diagram for this particular example more plausible, you have experienced first-hand the power of causal diagrams. Their graphical and straightforward nature make them a perfect candidate to communicate and discuss causal relationships among variables of interest with your business stake holders. Simply drawing any domain-specific causal graph will get everyone’s implicit causal assumptions on the table.
Apart from being a communication tool, how can causal diagrams bring us closer to accurate causal inference? Time for some theory again. Any causal diagram with more than two variables is composed of three possible patterns:
- Chains (A -> B -> C) [B a.k.a. mediator]
- Forks (A <- B -> C) [B a.k.a. confounder]
- Colliders ( A -> B <- C)
The causal graph in Figure 1 is composed of two chains and one fork. This has implications for the correlation structure of the data. First of all, being part of a fork, the correlation between search and closing can be blocked by conditioning on user satisfaction. That is, in a subset of customers with high (or low) user satisfaction the correlation between searching and closing should vanish. The same is true of the chains. By conditioning on user satisfaction we expect the correlations between satisfaction driver and searching/closing to vanish as well. In principle these implications allow us to test the robustness of our causal assumptions. In this example, we would first need to collect data on user satisfaction to be able to test our causal assumptions. Something that might not be obvious if we only focus on data that happens to be available.
Although it is never possible to prove a causal diagram to be true, the above procedure suggests how we can use the correlation structure in the data to falsify plausible alternative causal diagrams. More formally, the three patterns we discussed have different independence conditions. If we condition on B in a chain or fork, the correlation between A and C will disappear. In colliders on the other hand, conditioning on B will actually create a correlation that did not exist before.
The differing independence conditions have two important implications. First, as we saw before we can falsify some causal assumptions. Specifically, we can bring in data to distinguish between chains and forks on one hand and colliders on the other hand due to the qualitatively different correlation structure after conditioning. Second, data alone is never sufficient to answer all our causal questions as it cannot distinguish between chains and forks. Although a chain and a fork have very different causal interpretations, they behave similarly from a correlation point of view.
Fortunately, we often can also make reasonable causal assumptions based on logic and domain knowledge. For example it is intuitively clear that other variables cannot cause age. That is, no arrows should be directed towards age. Similarly we know that causes always need to precede their effect in time. Knowing the time dependencies among all variables of interest can go a long way in filtering out impossible causal diagrams.
All this focus on formulating a realistic causal diagram begs the question why we would bother if we can never prove which exact causal diagram is true. Indeed, in predictive analytics it is common practice to model all observed variables of interest as we simply aim to predict an outcome as well as possible. This is useful in cases where we have little hope in changing the outcome such as in weather or stock prediction. However, in prescriptive analytics we want to influence the outcome by performing an action. To do this effectively we need to identify a causal effect of action variable X on outcome Y. This is of course only useful in cases where we are able to influence the outcome such as in online advertising, churn prevention, and treatment recommendation.
In our example we want to estimate the effect of some satisfaction driver X — say membership cost or website usability — on account closing. To do this we need to accurately estimate the effect of X on account closing by conditioning for all confounders. That is, any variable in the causal diagram that (indirectly) causes both X and account closing. In fact, if we are willing to accept the causal diagram in Figure 1, we do not need to condition or correct for any other variable. If we further assume linear relationships between all variables this implies that the correlation between X and account closing is the causal effect we are looking for.
However, were we to collect data on user satisfaction, conditioning on that variable would destroy the true causal effect between our X and Y as it is a mediator. In fact even conditioning on search would have a similar harmful effect as it is a descendant of user satisfaction and therefore can be considered weak proxy for user satisfaction. This once again illustrates how — based on your causal assumptions — causal diagrams can be used to formally determine which variables to condition on and which you should definitely not condition on.
In fact algorithms exist that can do this for you. Given a causal diagram they can identify backdoor paths between your X and Y of interest. A backdoor path is any alternative path that contains confounders, variables that (indirectly) affect both X and Y. For example, the Python package dowhy asks you to provide a causal diagram, a data set, and the action variable (X) and outcome variable (Y) and then allows you to estimate the causal effect and refute causal assumptions based on the causal model and data you provided.
Although causal inference cannot replace proper experimental setups like A/B testing, they are a valuable analysis tool when A/B testing is either infeasible or premature. Now you know how to use causal diagrams in the context of causal inference. On one hand they help visualizing and communicating causal assumptions and on the other they can be used to identify which variables need to be conditioned on when estimating causal effects.
In the second post on causal inference in this series of two, we will discuss more elaborately how to estimate causal effects and finally get our hands dirty with some code. Stay tuned.