From DevOps to MLOps
DevOps has become an accepted practice in software engineering teams. We see a similar trend starting in the data science and data engineering domain, named MLOps. This blog post explores both and should give you a glimpse into what makes data engineering a specialization in the machine learning space.

DevOps
DevOps is a management approach where you try to optimize going from idea to measurable business value. Described well by AWS and Wikipedia.
In order to apply changes with confidence, a professional deployment approach consists of several environments to test changes before they are exposed to customers. Additionally, access control is in place, to protect customers from targeted tampering by developers. The simplest approach is having three environments: development (DEV), acceptance (ACC), production (PRD).
- Development is open for experimentation. Easy to add tech, easy to destroy tech, easy to manipulate.
- Acceptance is where we have a production like environment to test performance, check full integration and demo the feature to the business.
- Production is the environment customers rely on. It needs to be dependable: secure, private, reliable.
We start experimenting with ways to implement a new feature. If we have something we like, and verified that it works in the development environment, we promote it one step closer towards our customer.
In the acceptance environment, more extensive testing is performed. Checks on performance, integration with other components, security checks, etc.
If everything still looks good, the changes are moved to production, and finally realizing the business value that was envisioned. Of course, production undergoes continuous monitoring.
The above process can be graphed as shown in figure 1 below. Clearly, all these steps can not end up being manual work, as testing effort would grow with every feature. Therefore, a high degree of automation is required (a.k.a. continuous deployment).
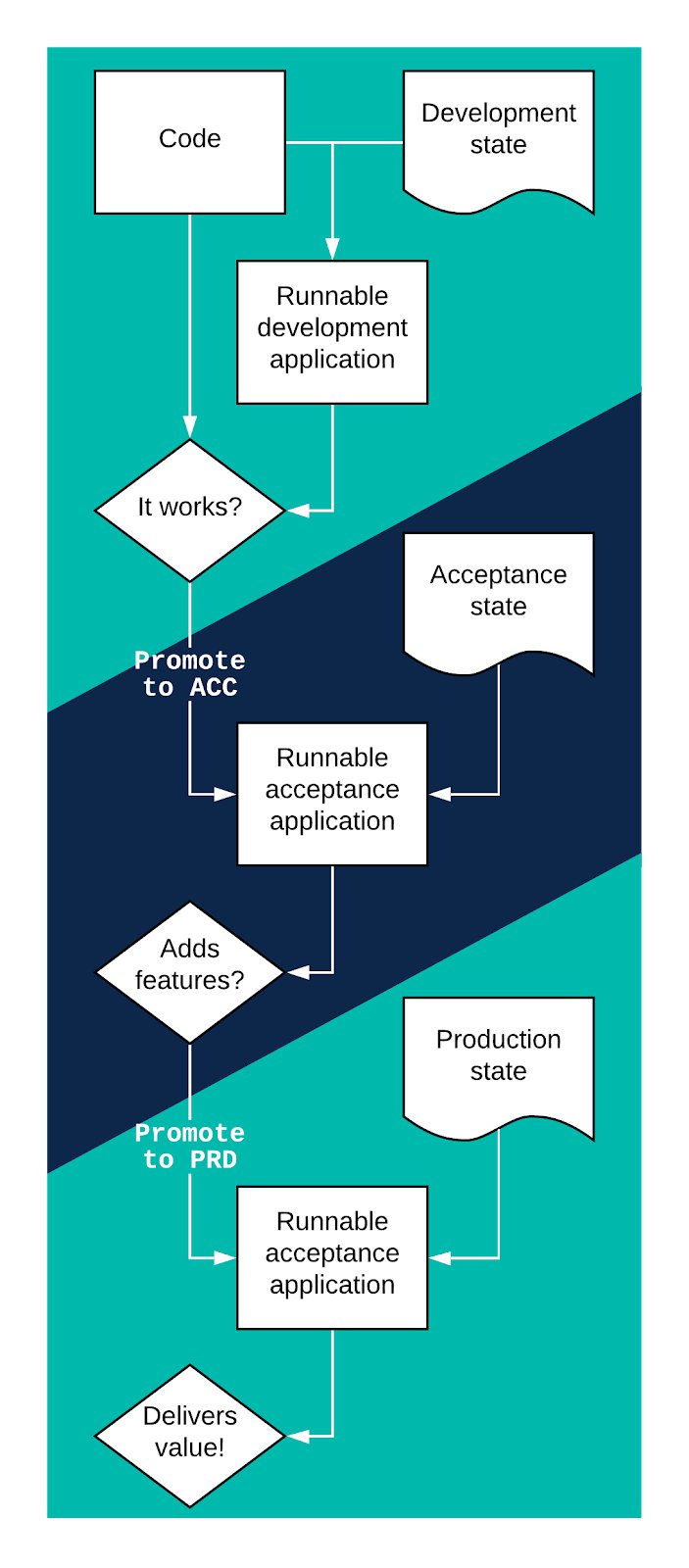
Figure 1: deployment graph from DEV to PRD
MLOps
Now that we know how to do DevOps for normal software, how about doing the same for machine learning?
We start with the same environments, because we need to have the same security in place and the same rigorous (automated) testing. However, where we had a feature written in code earlier, the first step now is to create the model with machine learning.
We take a machine learning algorithm, run it with our data and generate a model ready for inference. Models should be considered a smart summary of the data. This means that, as a default, the model itself should be protected as well as the dataset it was based upon.
As we have already seen a graph of DevOps in figure 1, lets go straight to a graph of the MLOps process:
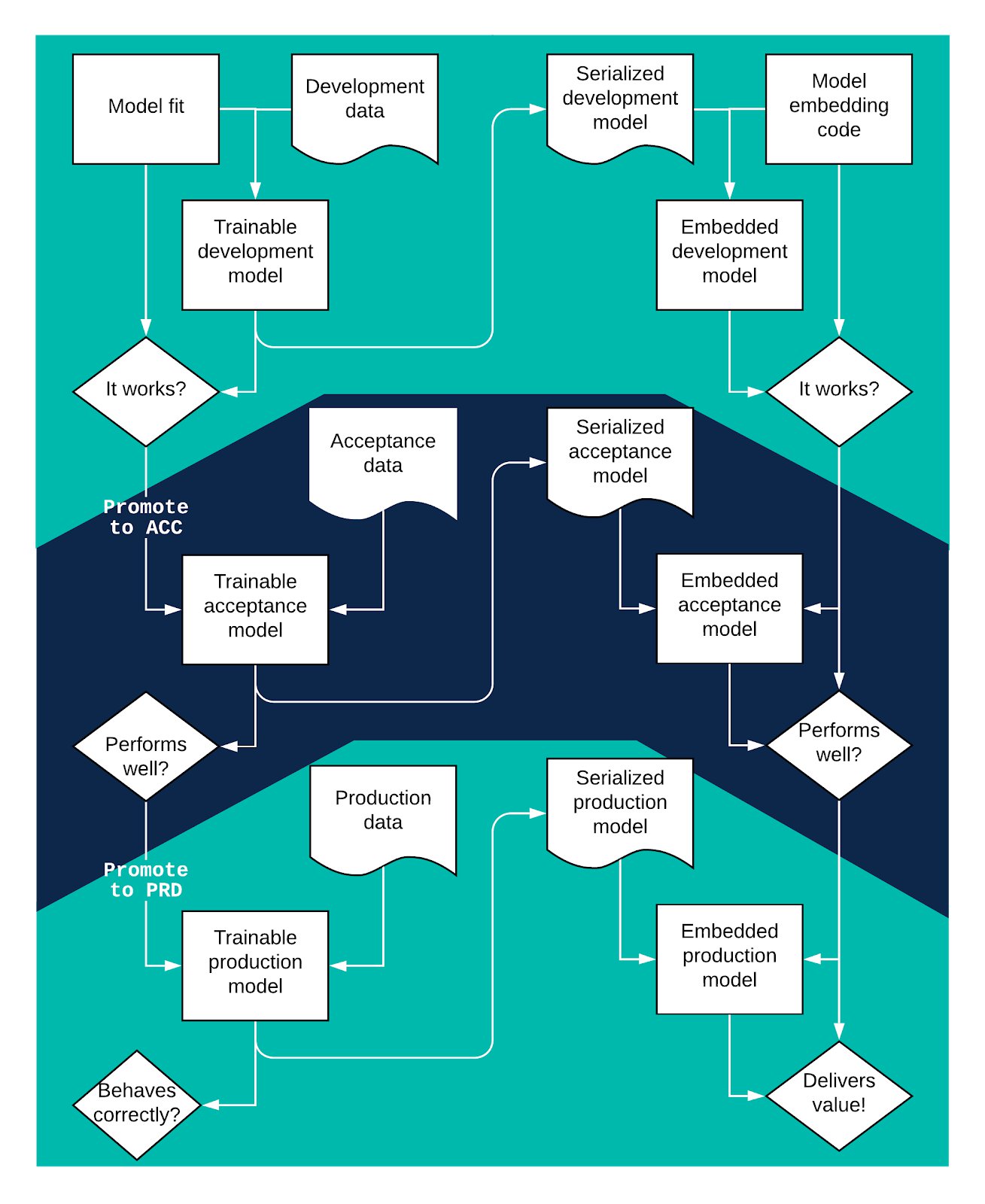
Figure 2: MLOps deployment
We start top left, work our way down and then, move to the right side of the process and start moving the trained model to production. As we can guess from looking at the figure, automating these steps is key to delivering machine learning value to your customer.
As you can see, figure 2 has a few more steps to process. If any of these steps consist of a hand-over to another team or involve manual labor, getting to production may take weeks instead of days.
Also note that training a model while keeping your data well separated and under strict access control will require scalable computing infrastructure in all three environments. To do proper MLOps you will have adopt DevOps practices. The alternative is a shortcut taken too often already: moving the whole left side, including your data scientists, into the production environment. You train and test models in production, move the serialized models into your development environment, then start the development process of embedding them into your application. Possible, but surely not professional in most situations.
Closing thoughts
With the introduction of the cloud, we often have scalable, resilient resources. This means that you could also have a virtual approach to environments. You may even make some datasets accessible across environments and others not. The same holds true for your serialized models, some contain sensitive data while others may not. If they do not contain private data you could consider moving your serialized production model to your acceptance environment.
That said, any movement of data between the three environments should be done consciously and explicitly: there are no shortcuts when it comes to the privacy and reliability of your platform.
Need help figuring out the shortcuts you are already taking? Contact any of our experts!.