Explainable AI: Understanding the Decisions of a Convolutional Neural Network
Diving into Local Interpretable Model-agnostic Explanations (LIME)
How can we define the quality of a convolutional neural network (CNN)? A model’s performance at a given task is often measured by some (simple) predefined metrics. There is even a place to compare the accuracy of state-of-the-art image-classification models on standardized datasets. However, if you are working on a project in the real world, what is the quality and value of a model if it has a phenomenal Top-1-accuracy? And what can be claimed about a model’s quality beyond these simple quantitative metrics?

Photo by Denny Müller on Unsplash
This is where Explainable AI (XAI) comes in. An XAI-system can be defined as “a self-explanatory intelligent system that describes the reasoning behind its decisions and predictions”.[1] Adding an explainable component to your ML pipeline not only provides model interpretability but may also enable business stakeholders to gain trust in your model or may be used to assess (and fix) systematic bias in your model.[1]
I will discuss the inner workings and pro’s/cons of several XAI methods that can be used in image classification projects. In literature, these methods are often referred to as pixel-attribution-methods, saliency maps, or sensitivity maps. For some methods, code is provided so it can be implemented in your own projects. All the code can be found here. This first blog aims to explain input-based attribution models, with a focus on Local Interpretable Model-agnostic Explanations (in short LIME).[2]
Methods
Many different methods exist to obtain pixel-attribution-maps. In general, the methods can be divided into two main streams: forward-pass (or input) based attribution and backward-pass (or gradient) based attribution models.
Part 1: Forward-pass (or input) based attribution models
These methods are model-agnostic. The main intuition behind these models is quite simple. Take an input image; make some adjustments to the input and observe the effect on the predictions. Adjustments can include for example partial occlusion or perturbation of parts of the input. Probably the most well-known example is Local interpretable model-agnostic explanations (or LIME).[2]

Lime | Photo by Shaun Meintjes on Unsplash
Local Interpretable Model-agnostic Explanations (LIME)
LIME can be used for all types of data and is not limited to image classifications. Although when used for explaining image classification models it’s often called a pixel-attribution-method, LIME does not work on individual pixels as these would probably not change the predictions very much. Instead LIME makes use of so-called “superpixels” which are small areas of the image grouped by location & color. These superpixel areas are used to perturb the image several times and identify what these changes do to the prediction. Eventually, the predictions on these perturbed images are used to train a more simple (and explainable) model, such as linear regression, to identify which superpixel areas are most important to predict a specific class.
Overview
Reading the original paper can be daunting at first, but the steps for creating the attribution maps are quite easy to understand when extracted:
1. Generate superpixel areas
2. Create perturbed images by randomly filling some of the superpixel areas with a solid black color
3. For each perturbed image:
a. Make predictions for the perturbed image
b. Create weights based on the difference between the perturbed image and the original image (smaller distance == larger weight)
4. Fit a simple interpretable model using the predictions on all perturbed images and the created weights.
5. Define the number of superpixels that should be plotted and plot the superpixels with the highest importance in the simple model (i.e. coefficient if a Linear Regression is used).
To provide a more visual overview of the steps see the image below. The left plot is the original image. The plot besides that demonstrates the outlines of all superpixel areas. The third plot depicts a sample of a perturbed image which will be used to identify how much the predictions will be changed by perturbing the black areas of the original picture. The last plot denotes the most important areas to predict the ‘toucan’ class according to LIME.
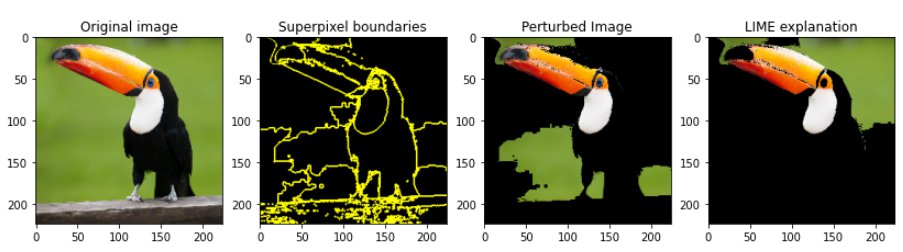
Multiple plots demonstrating a) the original input image, b) the boundaries of all superpixel areas, c) a sample of a perturbed image, and d) the most important super pixel areas to predict the ‘toucan’ class (Image by Author)
Pros and cons
One of the main advantages of LIME is that it is model-agnostic and can be used for any model. This also means that the underlying model can easily be replaced without having to adjust the code for explanations with LIME. In addition, LIME uses ‘simple’ comprehensible models to explain the decisions of a model, therefore as a data-scientist, it is easy to explain to the end-users. It is also one of the only methods that can be used for images, text, and tabular data. Therefore, if you work in a company with several models in production, it might be a good choice to pick LIME for explainability as the end-users only have to understand the intuition of one method.
The method also has some disadvantages. It can be computationally intensive, especially when working with large CNN’s as predictions have to be made for each perturbed image. There are also a lot of choices to be made when applying LIME: How many superpixel areas are appropriate? What simple model should be used for explainability? How many superpixel areas should be plotted in the explainability plot? These are all parameters that should be adjusted to your own situation and it can cost some time to find the optimal solution. Finally, the simple (interpretable) model that is fitted approximates the CNN but does not really explain it. There is no quality check on this model fit, so it may be misleading.
Hands-on
An example notebook on how to use LIME can be found in the following repository https://github.com/RikKraanVantage/explainable_AI. Included herein is the code necessary to replicate LIME explanations for your own project.
In the following section, the steps to reproduce LIME explanations for your own project will be covered accompanied by code snippets. The base model used for this example is a tf.keras.applications.EfficientNetB0 with pretrained imagenet weights, but any CNN can be used.
1. Generate superpixel areas
Superpixel boundaries (Image by Author)
For generating superpixel areas, the quickshift algorithm is used as implemented by scikit-image. This algorithm segments images based on color (and location), but more advanced clustering algorithms can be used as well. For this algorithm, a few parameters can be tuned (kernel_size, max_distance, and ratio). Basically, these parameters define how many superpixel areas are created. See https://scikit-image.org/docs/stable/api/skimage.segmentation.html#skimage.segmentation.quickshift for more info on how to tune these parameters.
2. Generate perturbed image
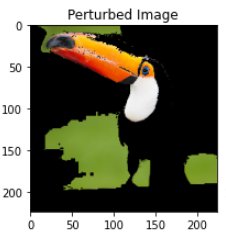
Perturbed Image (Image by Author)
Perturbed images are generated by creating perturbation vectors. These are binary vectors of length super_pixel_count. These vectors define for a specific perturbed image which superpixel areas should be perturbed and which should not. The number of perturbation vectors can be tuned, but be aware that increasing it comes with an increase in required computational power.
For generating perturbation vectors we use Numpy’s np.random.binomial() function.
Now we have a couple of vectors that we can use to perturb the image:
3. Predict for the perturbed image and generate weights
Predicting all perturbed images is simple, calculating the weights is somewhat more complicated. For creating the weights we first calculate the distance between the original image and the perturbed image. More specifically we calculate the distance between the perturbation vector of the original image (only ones, because no perturbation) [1, 1, 1, 1, 1, 1, ..., 1] and a random perturbation vector [1, 0, 1, 0, 0, 0, 1 ..., 1]. For this, we make use of sklearn’s pairwise_distances metric. Subsequently, we apply a kernel function to the distances to create the weights. This last step assures that the closer the perturbation vector is to the original image, the higher the weight will be. Why is this necessary? Let’s assume that we have a perturbed image with only 1 perturbed superpixel area. This sample is super valuable, as it provides a lot of information on the specific superpixel area (i.e. if the prediction for a specific class on the perturbed image is very different from that on the original image, we know that that superpixel area is important for predicting the specific class). In addition, if we have an image in which all areas are perturbed (vector of zero’s), the prediction for a specific class will probably be very different, only it provides little information on which superpixel area is important for the prediction.
4. Fit a simple interpretable model
The next step is to use the perturbation_vectors the predictions on the perturbed images and the newly created weights to fit a simple (and interpretable) model. A variety of models can be used and the easiest method is to use a sklearn model out of the box. For this example a DecisionTreeRegressor is used.
Note that the predictions that are put into the function should contain only the predictions on each perturbed image for the class of interest. So the shape of that vector is (num_perturbations, 1). The result is a vector that contains the feature_importance of each superpixel area for predicting the specified class.
5. Plot the explanation
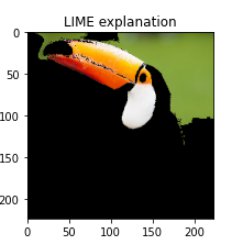
LIME explanation (Image by author)
Finally, the explanation can be plotted. First, the number of superpixel areas that will be depicted should be defined. This can be done by setting an importance threshold, taking a proportion of the total number of superpixel areas, or just by hard coding a number. In this example, I plotted 4 superpixel areas in total. According to LIME, it seems that the beak and the white area surrounding the eye of the toucan are important areas for the model to detect it (as these areas are the most important features of the fitted simple model).
Conclusion
This blog showed the intuition and pros/cons of one of the most used methods for XAI. The code snippets showed that implementing it is fairly straightforward. The next part will discuss and implement gradient-based attribution methods. Check the repository for all code examples: https://github.com/RikKraanVantage/explainable_AI
Sources
[1] Sina Mohseni, Niloofar Zarei, and Eric D. Ragan. 2020. A Multidisciplinary Survey and Framework for Design and Evaluation of Explainable AI Systems. ACM Trans. Interact. Intell. Syst. 1, 1, Article 1 (January 2020), 46 pages. https://doi.org/10.1145/3387166
[2] Ribeiro, Marco Tulio, Sameer Singh, and Carlos Guestrin. “Why should I trust you?: Explaining the predictions of any classifier.” Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. ACM (2016).