Enhancing Soil Insight With Efficient PDF Data Extraction
The case of Stantec

Matthijs Wesseling

Give us a task and we start digging! With Stantec we took a jab at their PDF extraction system, and helped them enhance their flagship product, the Soil Risk Map (SRM). We optimized the PDF extraction tool and increased extraction speed by 60 times, greatly enhancing the tool's performance. We overhauled the deployment model to develop an efficient cloud based product.

Digging into soil quality
Stantec, an engineering company focused on sustainable design with community in mind, tries to bring different specialists together to answer data driven questions. In the Netherlands Stantec specializes in soil quality and compliance, with their flagship product the Soil Risk Map (SRM).
The SRM is a multilayered map, allowing work planners and service engineers to quickly assess the situation when excavation work is required. Combined, these layers provide insight into whether excavation work brings in additional risks to your project, and whether special precautions are necessary.
Given the varied nature of the SRM, it uses many different data sources. This includes national databases, archeological data and soil research. Most of the information regarding contaminations in the soil, such as asbestos, is obtained from municipalities. Some of the data is already in an easily accessible XML format, but there is also a large corpus of PDF files containing analysis certificates. At the time of writing, the corpus consists of a quarter million documents and is still growing by 10-20 thousand files each month.
“Outsourcing innovative ideas is never easy. Luckily with BDR Stantec found a partner that does not solely what is asked. As with all innovation, you never know where you end up eventually.
BDR knew that well and remained critical along the way. They didn’t take the PoC as is, but reviewed it and fixed (critical) mistakes in it. They were also able to present the progress on the right level to the right public in various settings.
Thanks to BDR Stantec is fully confident that the output of this extraction tool can be used without introducing additional risks for our users, but with more information for their projects with less costs and time spent on research.”
~ Christiaan Jolly, Product Manager at Stantec
Elevating PDF data extraction
Manually extracting data from these documents is unrealistic, especially as some of the largest documents contain thousands of pages. That’s why Stantec approached us. Fortunately, we didn’t have to start from scratch, because they already had a simple proof of concept (POC). In this proof of concept they were already able to extract some data from the PDF’s. We were presented with the following requirements:
- Convert the POC into a well-tested minimum viable product with a stable deployment in the Stantec Cloud environment (Microsoft Azure).
- Increase the success rate of the POC from the current 12%.
- Properly handover knowledge of the final product to Stantec’s engineers, so they can continue working with it.
While the POC had some of the groundwork done, the data was not yet in a format that could be ingested into the Soil Risk Map, so new components needed to be added as well.
Besides these requirements, there were some additional challenges that further complicated the project.
- The data extracted from the pdf’s needs to be of extraordinary quality. Missing a measurement or misreading a number can have very real consequences.
- Limited cloud access. Stantec was in the middle of a migration to Microsoft Azure, and was still developing procedures for allowing access to contractors.
- Limited access to data, for the same reasons.
Because of the strict quality requirements, we ruled out processing scanned documents. During development, we only had about 1% of the total corpus to train and test with.
How we cut PDF extraction times by 98%
One of the first issues we encountered when we started investigating the POC, is that it ran incredibly slow. The largest documents took several minutes to be processed, which is unacceptable given the large corpus. Slow run times significantly hinder both usability and ongoing development, as the long iteration process considerably slows down progress. After analysis, it turned out that the main offenders were PdfPlumber and Camelot-python, two packages used for ingesting the PDF files.
PDF is a difficult file format to work with, because of its complexity. A parser needs to be very flexible, in order to handle a wide range of data types. This flexibility makes something as seemingly simple as extracting text, in fact very difficult. Combine this with python’s inherent slowness and it becomes apparent why PdfPlumber and Camelot were giving issues.
It was clear that pure python packages were not going to work, so we went on the hunt for a replacement. Following thorough research and testing, we opted for XPDF, one of the original open source PDF tools that remains in use today. XPDF has over 27 years of ongoing development, and is actively used, making it an attractive and reliable choice. The tool has a few additional benefits:
- It already has the `pdftotext` feature, which supports text extraction with character positions preserved. This is extremely valuable for parsing tables.
- It is written in C++, which makes it very fast, and easily integrated into python code.
- It is licensed under the GPL v3 license, allowing us to modify it and integrate it into our extraction tool.
The open source python wrapper we developed (XPyDF) can be found on github, or installed with pip. After replacing the PDF ingestion tools with XPyDF, the extraction tool ran over 60 times faster (a 98% decrease), with some parts of the pipeline showing speedups of 9000 times! Combined with the superior quality of XPDF’s output, the decision was a great success.
Working with (very) limited data
In order to handle the strict quality requirements, we implemented a custom error-handling framework with detailed error messages. This allows for failing early and gracefully when an unexpected scenario is encountered. Combined with scripts for aggregating these errors after a run, we can easily identify bugs and fix those that will have the largest impact. The way these errors are thrown is extremely strict, as we favor quality over quantity.
Harnessing Data-Driven Performance Insights
During development, we constantly improved components and added new ones. This meant the success score of the tool was constantly changing. We wanted to easily track those changes, in a data driven way. Especially in the later stages of the project, we needed to be able to use our time as efficiently as possible, making improvements that have the highest impact. To achieve this, we created a visualization tool with the help of plotly’s built-in Sankey Diagram. With this visualization, we can easily compare performance between versions and determine which components need the most improvement. After each change we simply re-run the pipeline on the test data, to confirm the change worked as expected.
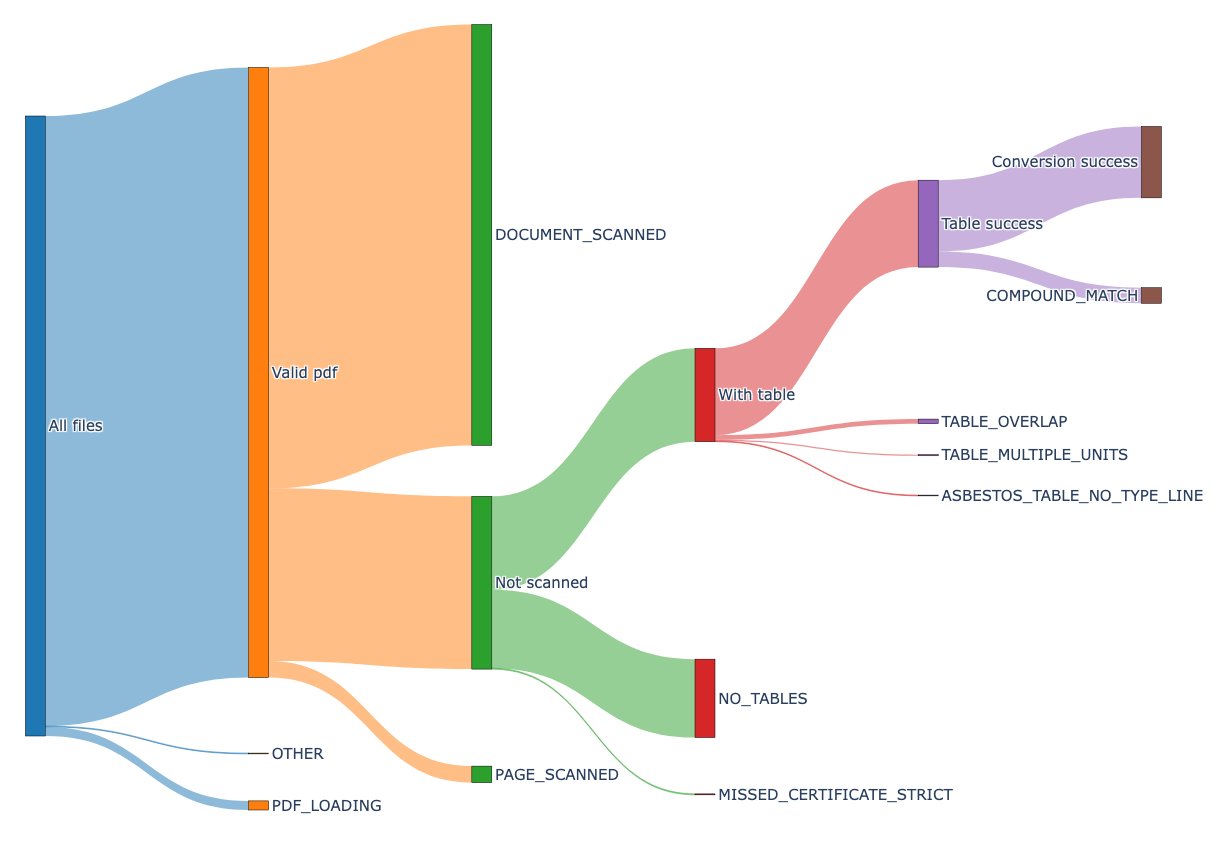
An example of the visualization we used on testing data.
Creating an efficient deployment
To deploy the model, we use a function app, a container instance and 3 storage containers. These containers consist of:
- Input container: Contains the pdf corpus
- Data-batch container: Which runs the extraction tool
- Results: The extraction output is stored here.
The function app selects unprocessed pdfs and uploads batches to the data-batch container at regular intervals. Then, the data-batch container processes them, and moves the output to the results container where it is stored.
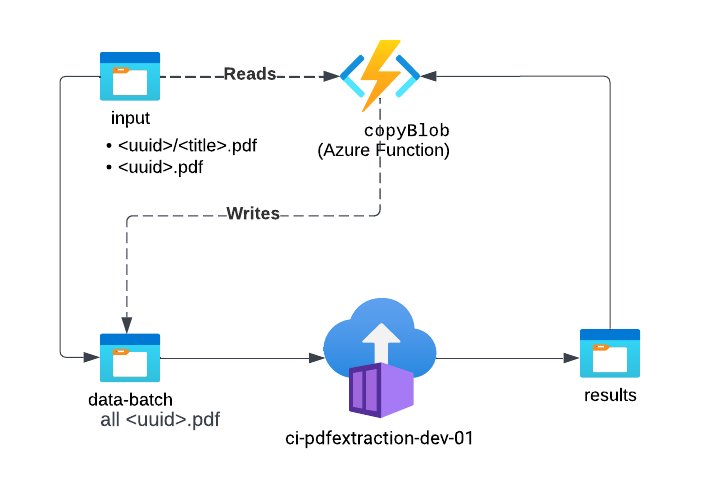
Architecture of the deployment.
Conclusion
After 4 months of work, we completed all the goals we set out to achieve. We were able to successfully process 24% of all the documents, significantly improving on the POC which was limited to 12% of the documents. We added the missing components and put in strict quality checks for every process. This has resulted in a trustworthy extraction tool, with an efficient and reliable deployment in Microsoft Azure.