Data science is boring
Or at least a big part of it should be
TL;DR Data scientists should become MLOps Engineer or an Analytics Translator.
We keep doing the same things over and over again
In my experience as a data science consultant, I see many companies doing the same things over and over again. Which is odd, because data scientists (as partly technical people) can be expected to automate repetitive tasks. Indeed we have many tools available to automate common tasks. Hardly any data scientist I know is still programming their own machine learning algorithms. We all use Scikit-Learn and other libraries to train decision trees and the likes. Many of us use MLflow or similar tools to keep track of the experiments we run and the models we train. But time and again data scientists everywhere are reinventing the wheel when it comes to applying these tools and tying them together.

Over and over again...
Why do we do it?
Of course we could say that every project is unique and that you can only reach optimal performance for your model if you make very specific choices in your specific setup. But let’s be honest here — nobody needs to produce a Kaggle-winning-performance-level model (unless you’re competing on Kaggle, of course). You simply need to build a model that works well enough for its purpose. The 80–20 rule usually applies and spending 80% of your time on squeezing out that final extra percentage point of accuracy simply isn’t worth it. Instead you could have built 4 more models that deliver a lot more business value.
Furthermore, in a larger organisation, maintenance of models is much easier and much more efficient if they are always set up in the same way. A bunch of models using a common code structure are much easier to maintain, especially for someone other than the original developer.
So, again, why do we do it?
Well, basically: because we enjoy doing it. We became data scientists for a reason. In my case, I like to solve puzzles, and the underlying principles of deep learning are hugely fascinating. Gradient boosted trees algorithms such as XGBoost and LigthGBM are really quite clever, and using such an algorithm to achieve state-of-the-art performance makes me feel quite clever myself.
Gathering data and feature engineering are simply not as rewarding; to get any results, it is the 80% of hard work I (unfortunately) have to do before I get to the fun part of implementing the algorithm.
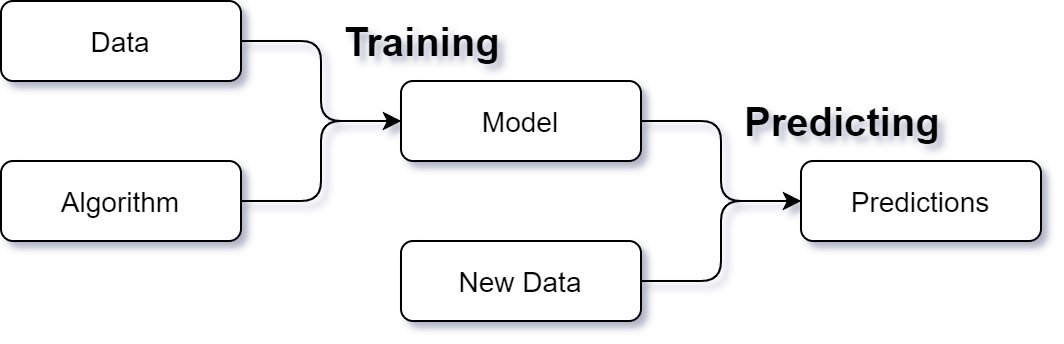
Simplified machine learning process
Most data scientists dealing with machine learning respond in a similar way: they are mostly interested in the machine learning algorithm and the model it produces; I imagine because of reasons very similar to my own. So gathering data and feature engineering is something we unfortunately have to do before getting to the fun part.
On the other hand, in all fairness, I (and literally every data scientist I know) have never developed a gradient boosted trees algorithm myself.
What does that tell you?
Before we get to that, let’s first ask ourselves the following question:
What is it, that makes each of our projects unique?
And conversely, which parts are often the same, and should we be able to automate?
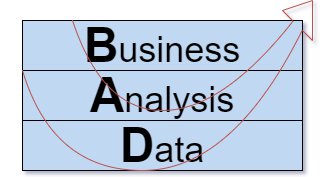
- A good data science project starts with a clear Business purpose. Why are we doing it? How is it going to benefit the business? The business purpose of our model is definitely unique to our project.
- While the detailed Analyses are different from one project to another, the scientific method and the machine learning process are not. In particular:
- the machine learning algorithm is usually generic, but
- the choice of algorithm can be considered specific to our project;
- for structured tabular data, however, it is presently quite universally true that a gradient boosted trees model will perform best, and there is not much of a choice here. - Directly related to the purpose of our model is the Data, i.e. the target and feature variables for our model.
- The target and perhaps some of the features can be expected to be unique to our project.
- When we’re building multiple related models, many features are likely to be useful across projects. - Model evaluation and the validation of our Analysis are closely related to the algorithm, or more specifically the type of model. For example, classification models are typically evaluated based on metrics such as accuracy, precision and recall, or the area under an ROC-curve, while regression models are typically evaluated using a mean squared error or similar metrics.
- The Business validation and implementation are closely tied to the business purpose of our project, and usually very specific for this project.
From the list above, we can conclude roughly that the business layer tends to be very specific to a project, the analysis layer tends to be quite generic (providing opportunity for automation), and the data layer has some specific and some generic aspects.
Now here is the problem: many data scientists are technical creatures. And as such, they like to focus on the machine learning part of the job. The business layer is often dealt with by someone in a Product Owner or similar role. Allowing (or even, forcing?) the data scientist to focus on the analysis and data layers, of which data gathering and preparation easily takes over 80% of their time. They only spend a small part of their time on actual analysis and building a model. Accepting that
“you only need to build a model that works well enough”
means that you’re likely to spend an even bigger part of your time on those not-so-interesting data gathering and preparation tasks, rather than playing with the newest, fanciest machine learning algorithms.
The bottom line is: instead of working towards a more boring job, data scientists prefer to check out the latest, greatest, shiniest algorithms. If this sounds familiar, from a business perspective this should seriously get you thinking!
So what can we do?
The good old days where a data scientist was that unicorn-combination of a hacker-mathematician-with-business-sense are over. Especially the hacker part. Get rid of any data scientist who doesn’t care about building decent software. You don’t have to be an expert programmer to know that throwing a crappy experimental Jupyter Notebook over the fence for deployment is a recipe for disaster. As data science becomes a serious driver for business value it deserves to be treated as such.
Moving forward, data science is expensive. So if you really want your organisation to benefit from it, automate as much as possible. That includes both exploratory analyses and model development and deployment, but also data and infrastructure management. A modern framework for dealing with such topics is often called MLOps: a combination of Machine Learning and DevOps. Google published this article on MLOps, which explains the stages of maturity through which your organisation can progress, culminating in fully automated CI/CD pipelines for machine learning.
On a slightly more tangible level, don’t forget to automate smaller recurring tasks. Throughout my career I’ve produced countless ROC curves for various organisations, and every time I have found my self searching the internet for the exact matplotlib and sklearn.metrics.roc_curve commands I need. So recently I’ve started a project called MyAutoML, an open source library that aims to fill this gap: allowing data scientists to focus on what makes their individual projects unique, by providing tools to automate machine learning processes. At present it is very far from complete, but feel free to explore the code and use what you find. Contributions are more than welcome, so if you have any ideas or suggestions, please get in touch!
At the other end of the data science spectrum is the business analysis, the top layer of the data science cake. As my colleague Dennis Ramondt wrote in his blog: you don’t have enough Analytics Translators. You can train business experts to understand the basics of machine learning, but also make sure your data scientists spend more time in the role of Analytics Translator. The person building a model should spend as little time as possible on coding that model (use standard algorithms) and as much time as possible on analysing the business, making sure they’re doing the right thing. Often unduly ignored by decision makers in business units as IT specialists, a good data scientist is trained to analyse your business and spot opportunities to generate business value from your data, not just to program a machine learning model.
Conclusion
The role of the data scientist in an organisation is changing. The traditional unicorn role seems to be fading, making way for MLOps Engineers and Analytics Translators. The former is the evolution of a data scientist into a serious and mature machine learning platform/software developer. The latter is the evolution into a business-focussed analytics expert.
Whichever path you choose, there are many interesting challenges ahead and many puzzles to solve. Just make sure you don’t become that data science dinosaur who’s stuck in Jupyter Notebooks while the world has moved on!