A customizable IoT Platform with minimal effort
Using AWS Timestream, FastAPI on Lambda and HTTP API

Imagine that you invest in wind turbines and you even build them in your backyard. To ensure that you have full insights into the performance of your investment, you install sensors to measure power production and place a weather station. But how do you get this data into the cloud in a practical way? As my colleague Jaap de Koning and I pondered about this hypothetical situation, we set off to invest the latest technologies on AWS.
This blog discusses new functionalities that lets you setup your own IoT platform with minimal effort. The new functionalities may provide answers to common architectural questions like:
- How to create an access point?
- Where to store the data?
- How to perform analysis on the data?
We will provide code snippets to make our discussion concrete.
New functionalities
If you do not want to spend time on managing technical components and performing server updates, serverless can be a good choice. AWS recently launched a range of new features and services, that have made development a lot simpler:
- AWS Timestream is a new serverless timeseries database, released in 2020. You are billed for write and read operations, and for storage duration.
- AWS API Gateway introduced the new HTTP API in 2019, which makes integration with AWS Lambda simpler. API Gateway is a serverless reverse proxy (like NGINX), and operates as a single access point to expose services using a public URL.
- AWS Cloud Development Kit (CDK) is an infrastructure as code framework, which can be used in various languages (Python version released 2019). CDK code translates to CloudFormation templates.
Outside of AWS:
Wind turbine experiment
As an experiment, we will simulate 770 Dutch wind turbine projects, that send data to AWS. You will see what it takes to set up API Gateway, Lambda and Timestream and make them work together. By the way, all three services are under heavy development, so we expect even simpler and better solutions than ours to appear soon.
We describe the simulation at the end of the blog. In a nutshell, to generate realistic data from the turbines, we use the specifications from windstats.nl and real-time weather data from openweathermap.org to drive the turbines. Each turbine periodically sends data to AWS. Data from all turbines is aggregated to obtain the total produced power in the Netherlands.
The questions that we will answer:
- How to define a Timestream database in Cloud Development Kit?
- How to insert data into Timestream with Python?
- How to create a URL with API Gateway and invoke Lambda?
- How to send data from the wind turbine to the URL with HTTP?
And finally:
- How to query data from the Timestream database?
Server side: receiving and storing data
HTTP or MQTT
For up- and downloading data over the internet, both HTTP and MQTT are commonly used protocols. MQTT is available on AWS in IoT Core, and is the subject of a future blog. This blog focuses on HTTP. One reason to opt for HTTP is the flexibility it gives you to incrementally expand your service, while MQTT on IoT Core requires you to set up complex security.
Why focus on serverless?
Serverless services have advantages over setting up your stack on virtual machines or managed services that require you to choose ec2 instance types. Following the definition of the Cloud Native Computing Foundation, serverless shifts several responsibilities from the developer to AWS:
- server provisioning
- maintenance
- updates
- scaling
- capacity planning
None of these responsibilities are of our concern. Sounds good, right? Especially if you’re in a small team or even on your own.
AWS serverless services do not require you to use a Virtual Private Cloud (VPC). Therefore, you don’t need to specify networks and security groups for the services you use. Instead, AWS IAM is used to manage access to resources. In the stack described here, authentication can be placed in the FastAPI code, or can be handled by API Gateway.
Read more about the advantages of a serverless approach in our free whitepaper: Achieving Servitization.

Whitepaper: Achieving Servitization
How serverless technologies minimize adaptation for industrial manufacturers
Key technical steps
The diagram below shows the used AWS components. The blog will first discuss the server side from right to left, then the client side, and conclude with analysis of the data (“office side”).
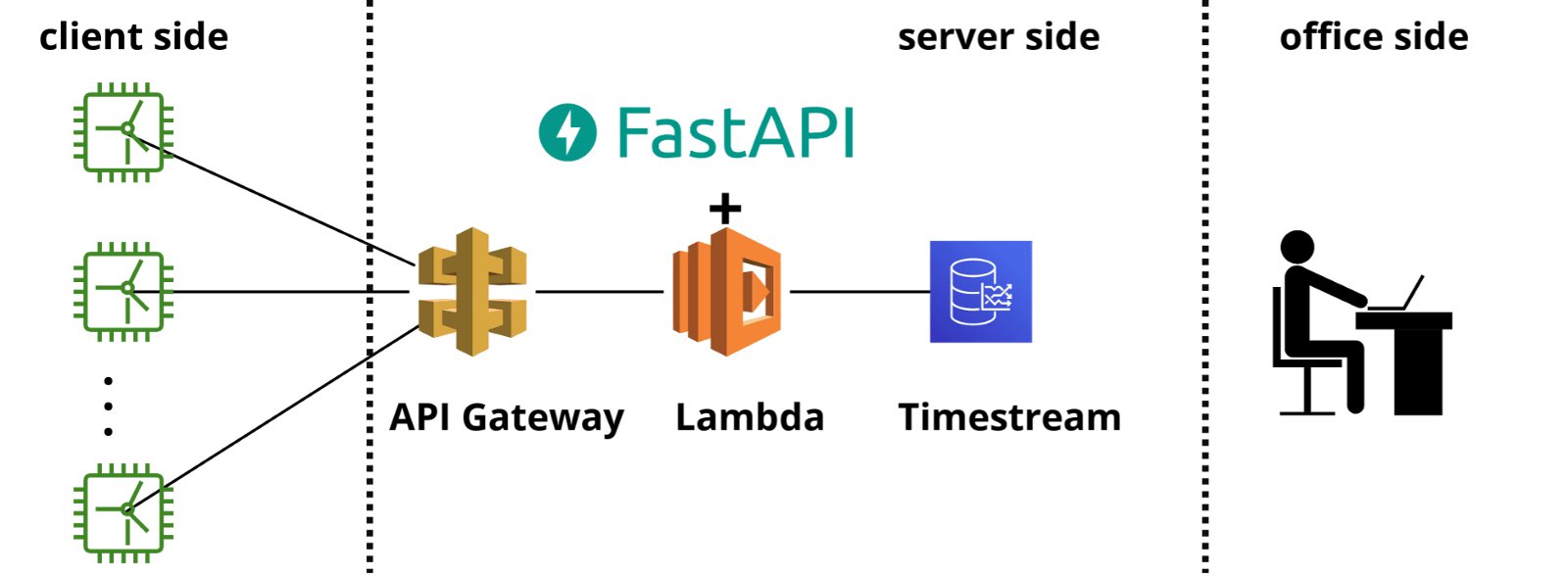
Data flows from left to right: data flows from turbines to API Gateway, to Lambda, to Timestream.
We will run through the key steps to create this stack on AWS:
- Data is written to Timestream from the FastAPI in Lambda.
- Lambda is invoked by API Gateway.
- API Gateway receives data from the wind turbines over HTTP.
Timestream
Defining a Timestream database in CDK is simple, and comes down to choosing:
- a name for the database
- a name for a database table
- the retention period of the data
After the retention period, data is deleted. No custom table schema is needed in timeseries databases, as opposed to SQL databases.
FastAPI in Lambda
Data is written to Timestream from Python code that lives in Lambda. The (very) minimal example below writes data that arrives via an HTTP POST request to Timestream using boto3. When a data point is stored in a dictionary, then the keys must comply with the write_records format.
The code below also reveals the Timestream data model. You provide a timestamp with a measurement value. This data is enriched with tags that serve as metadata for the measurements. After insertion, you can filter SELECT queries using those tags.
To run FastAPI on Lambda, the Mangum adapter creates a handler object and converts messages from API Gateway to data_points. All you need to know, is that you need the statement in line 22 to make FastAPI runnable on Lambda.
Data insertion into Timestream is done in a single statement, starting on line 17.
API Gateway
This is the last service that we need on the server side. API Gateway provides:
- a subdomain to send data to (may be extended with AWS Route53)
- functionality to automatically invoke the Lambda function
- numerous features possibly needed in the future, such as mutual TLS
With the release of the HTTP API, invoking Lambda from API Gateway has become a lot simpler compared to the old REST API. The CDK code below creates an HTTP API that will invoke a Lambda function. We left the code to define the Lambda function out, good examples are found here.
Client side: Uploading data from the turbines
Data from the wind turbines is uploaded frequently to the API Gateway using an HTTP POST request. The Python script gets the current wind speed, then calculates the produced electrical power and adds a timestamp. Each metric is then sent to the API_GATEWAY_URL using the httpx package.
In the wind turbine simulation, we ran 770 parallel Python processes, each representing a wind turbine project. Even when all wind turbines were uploading data simultaneously, the platform was stable and no data was lost. More than 100 concurrent invocations of the FastAPI code on Lambda frequently occurred without any errors.
Note that this is a minimal example. For production, more fail-safe and maintainable code should be used.
Office side analysis: Timestream to Pandas
Queries on Timestream can be made using boto3, which is relatively straight forward. For conversion to Pandas, the package AWS data wrangler may be used, but a short conversion script is feasible as well. Below you find a snippet with the required statements. The result is a Pandas DataFrame with all data and metadata from the past 24 hours.
Results of the experiment
Simulation: Behind the scenes
Wind turbine model
To simulate a wind turbine that is to some extent realistic, we use wind turbines in the Netherlands (from windstats.nl), and real-time weather data from Openweathermap. The wind turbine parameters are:
- nominal power in kilowatt
- the brand and type
- the number of turbines on the site
- the municipality to estimate coordinates.
Openweathermap allows lookup of the wind speed. The provided wind speed is at 10m height (so not at turbine height).
Speed-power curve
To map the wind speed to the turbine power, we estimated a speed-power curve from wind-turbine-models.com. The website lists numerous power curves, which typically show minimal power production until 4 m/s wind speed, and then linearly increase to nominal power at 11 m/s:
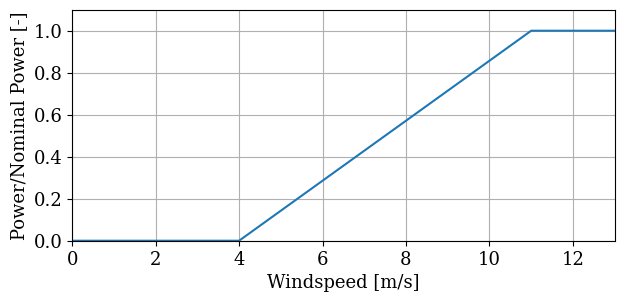
Normalized power against wind speed. The curve was estimated using data from wind-turbine-models.com
Analysis: how much power produced?
The figure below displays the electrical power per project. Data was produced on December 19th 2020, in the afternoon.
The simple model used here predicted a total power of 527MW, but energieopwek.nl reported almost 2GW. We partially explain the gap by an underestimation of the wind speed, since we used wind speed at 10m height. At turbine height, the wind speed may be more than 50% higher, which may increase the produced power by more than 50%. An improved model may be part of a future blog.
A clickable version of the power plot is found here, used wind speeds here.
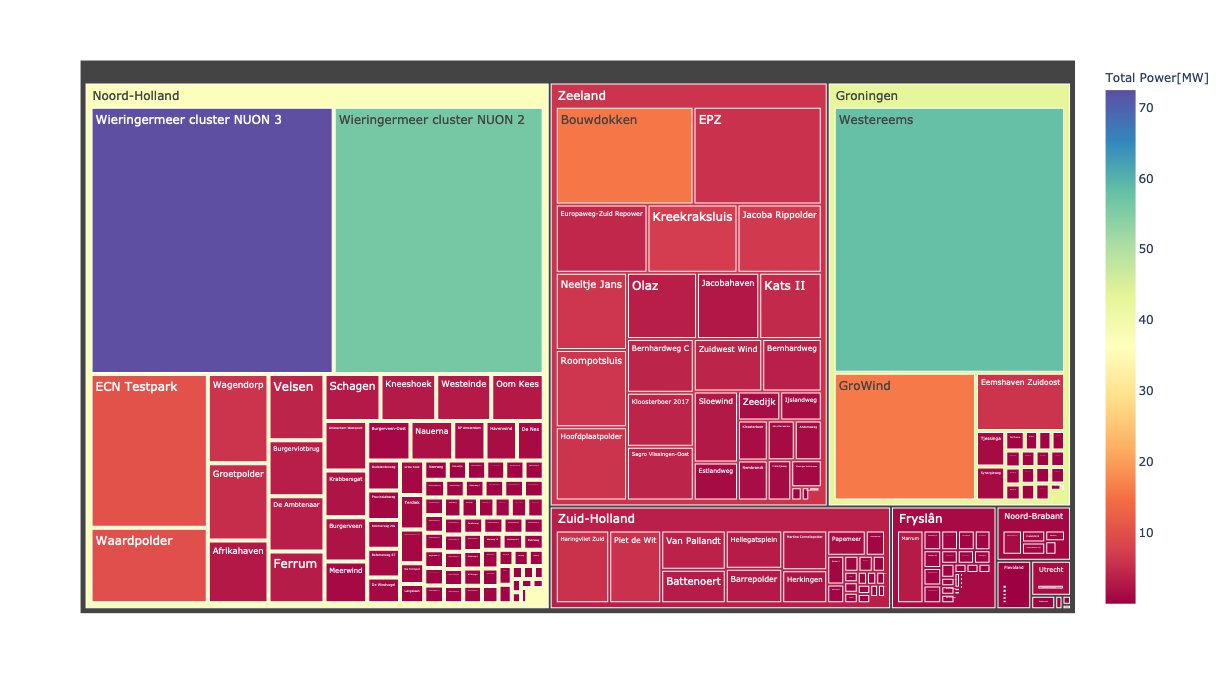
Wind power per project. Plot made using Plotly.
Conclusion
AWS is rapidly developing its serverless services. Recent developments in API Gateway, the new Timeseries database and Cloud Development Kit can make the cloud stack a lot simpler. In this blog, we showed how these tools make up an IoT platform, which is extendable and customizable.
To test the stack, we simulated 770 wind turbine projects in the Netherlands. The platform was very stable, even when all wind turbines were uploading data simultaneously. Querying the Timestream database is fast and simple. After running it for a while, almost all the cost was due to the use of Timestream. With a few GB’s of data ingested we spent about $1.50.