Cost comparison of deep learning hardware: Google TPUv2 vs Nvidia Tesla V100
Google offered us a chance to test their new TPUv2 devices for free on Google Cloud as part of the TensorFlow Research Cloud program. In this blog post we will show some of the experiments we ran to test model accuracy, development speed and runtime. We have found that TPUs have an insanely fast data throughput relative to their cost. Initially, when using the Adam optimizer, we found a bug in Tensorflow that made model accuracy lag behind that of models trained on more conventional devices such as CPUs and GPUs. This bug has since been fixed by Google engineers and this article has been updated to reflect those changes.

Experiment
We ran all of our experiments on a relatively small convolutional network since we didn’t have access to the TPUs for that long. This definitely skews the results somewhat as distributed learning (in both GPUs and TPUs) works best when using larger networks and datasets. The networks were trained from scratch on Fashion-MNIST. Note that this custom network is not officially optimized for TPUs.
We ran the experiment with the following devices:
- CPU (no distributed learning)
- 1 TPUv2 with only 1 core active (no distributed learning)
- 1 TPUv2 with 8 cores (distributed learning)
- 1 Tesla V100 GPU (no distributed learning)
- 8 Tesla V100 GPU’s (distributed learning)
All of the experiments were run on a Google Compute n1-standard-2 machine with 2 CPU cores and 7.5GB of memory, with the exception of the experiment with 8 Tesla V100 GPU’s, where 30GB of memory was given to the machine due to excessive swapping.
To account for any differences in the convergence speed of models (primarily due to data parallelism) we do not train a specific amount of epochs, but instead train until a validation threshold of 0.25 (log loss) is reached. This makes for a fairer comparison.
Below we show a comparison of the training runs between these five device types and show some interesting results. For every run we have tested both tf.train.Adam optimizer (with default settings) and the SGD optimizer with Nesterov momentum (0.9): tf.train.MomentumOptimizer.
CPU baseline
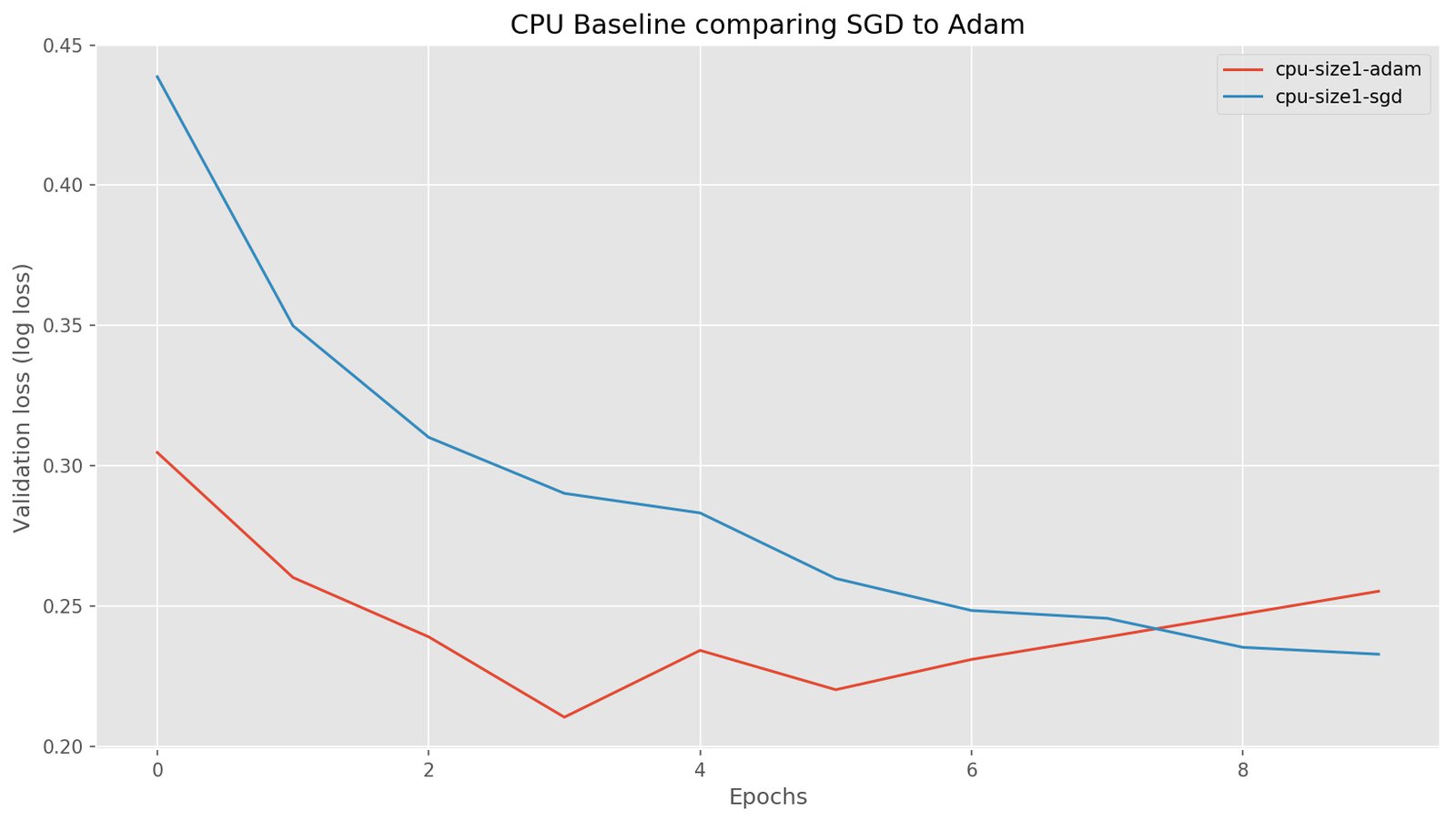
In this graph we can see that on CPU, the network reaches a low validation loss rather quickly. In this case Adam reaches a low point a lot faster than SGD but does overfit in the end. Adam being faster makes sense as we didn’t do any learning rate tuning for the SGD optimizer.
Single GPU: similar results
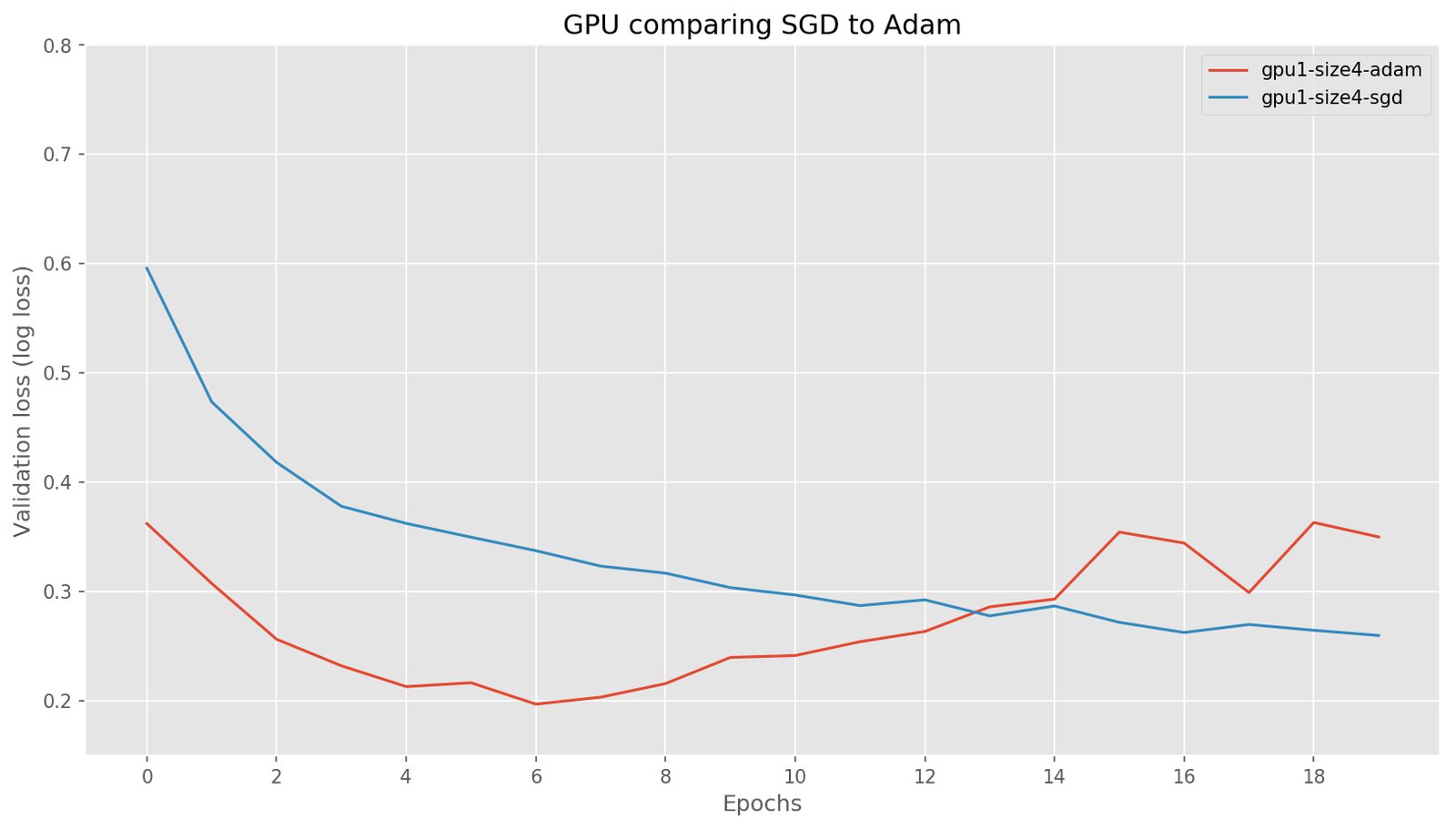
Again, we see the network converging quickly and that Adam is faster than SGD but does overfit a bit in the end. The most important thing to note is that training a network on a GPU does not give different results compared to CPU.
Data parallelization using 8 GPUs
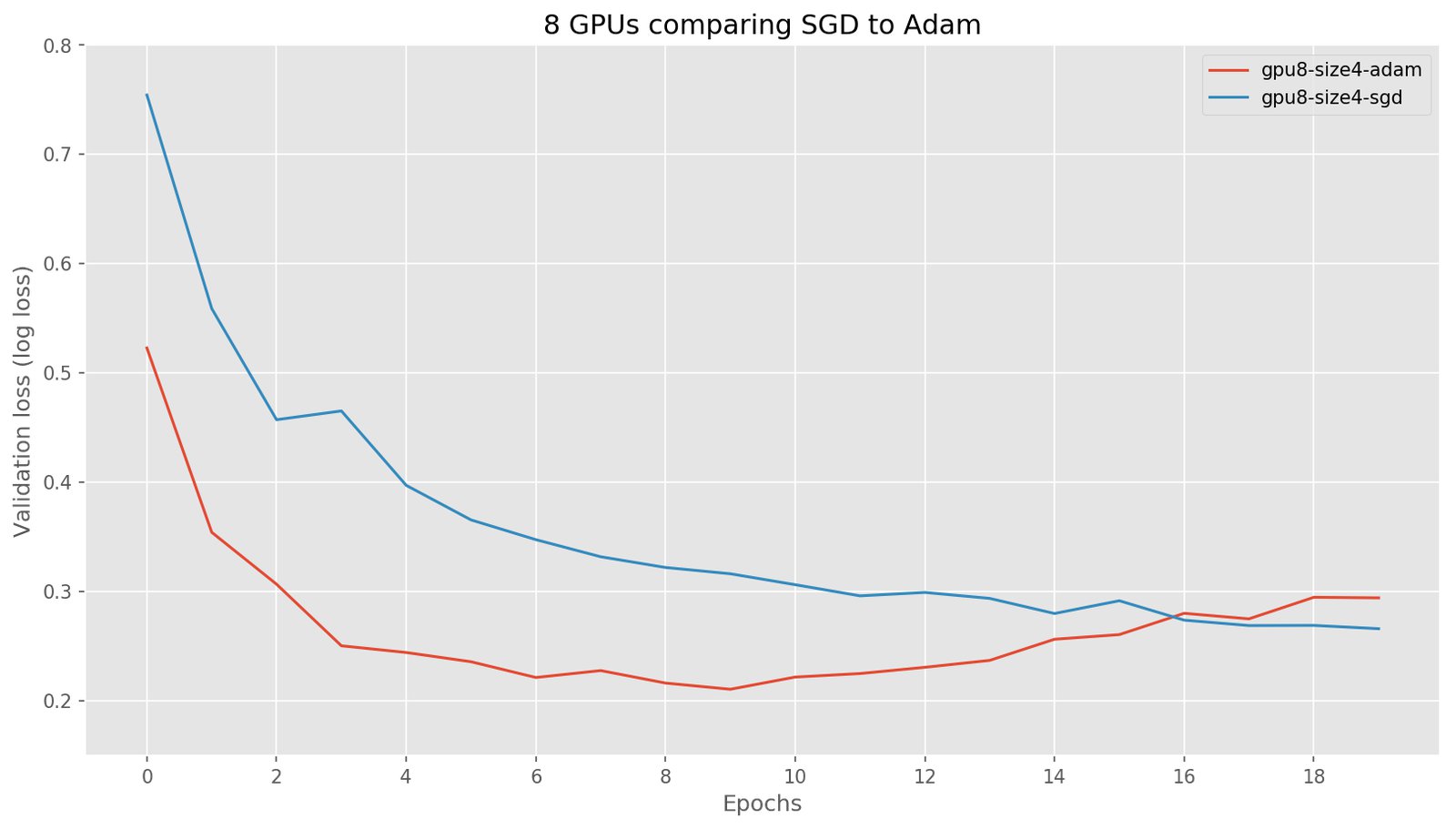
When we train the network on 8 GPUs using data parallelization, we can see that training requires the same amount of epochs to reach the minimum validation loss. Since data parallelization decreases the number of effective updates per epoch, we increase the learning rate linearly with the batch size, as suggested here. In our case this means increasing the learning rate 8-fold. In terms of wall time, using 8 GPUs is significantly faster than using a single GPU. In larger networks, the speedup would be close to 4–7x. In our smaller network, the speedup is slightly smaller with a 3.7x speedup.
TPU with 8 cores
We now take a look at how the performance of TPUs compares to GPUs.
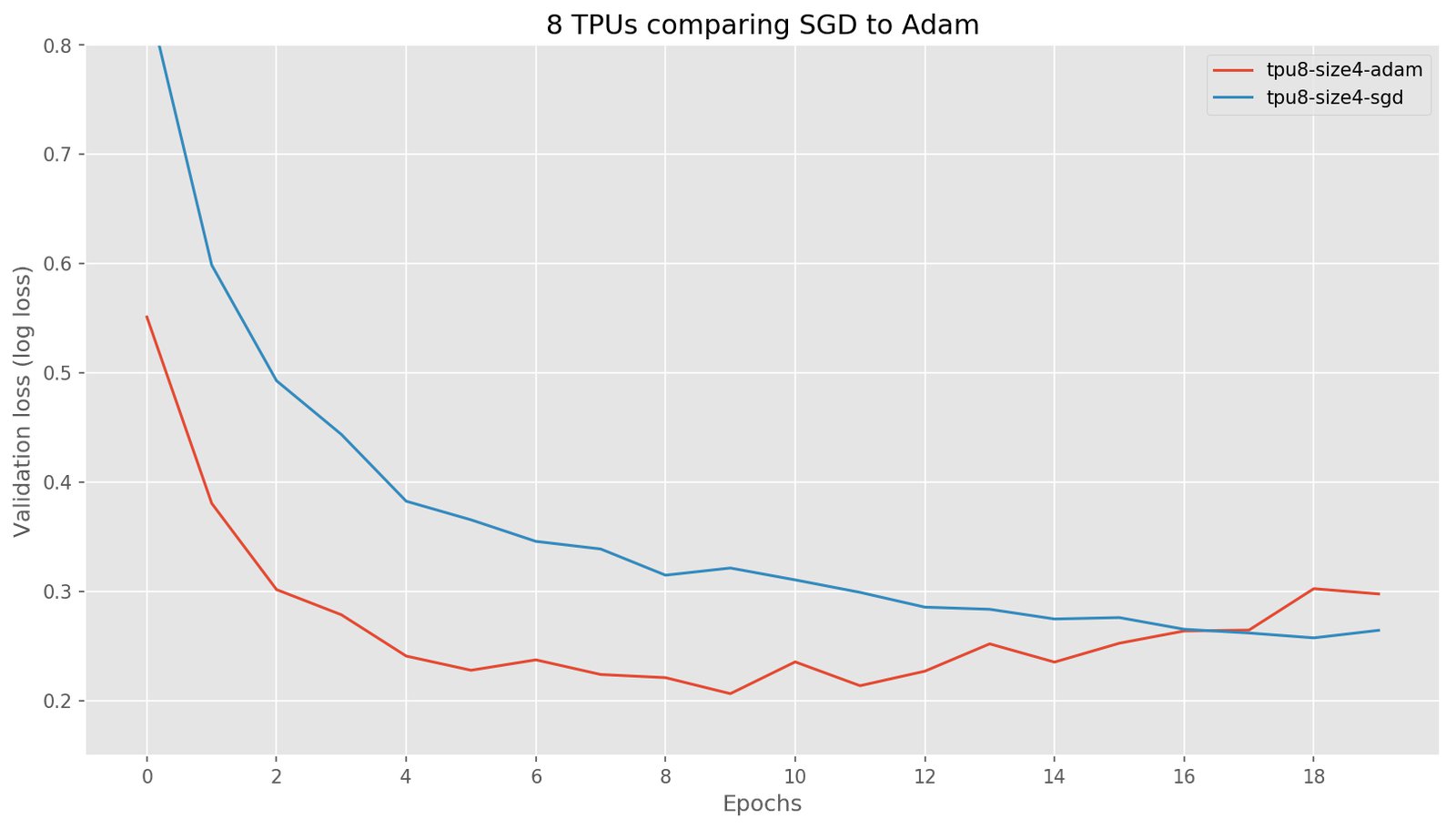
Comparing TPUs with GPUs:
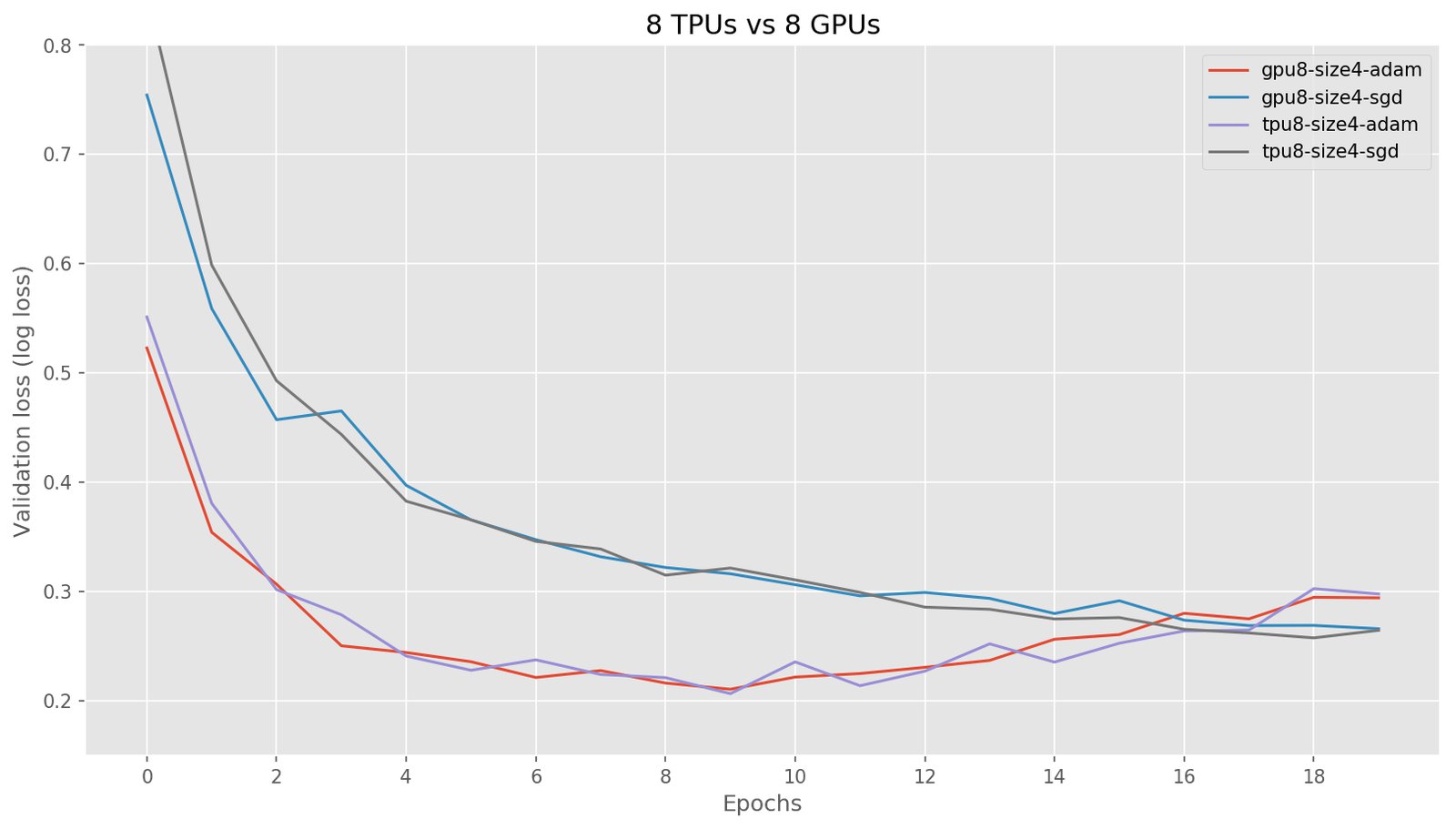
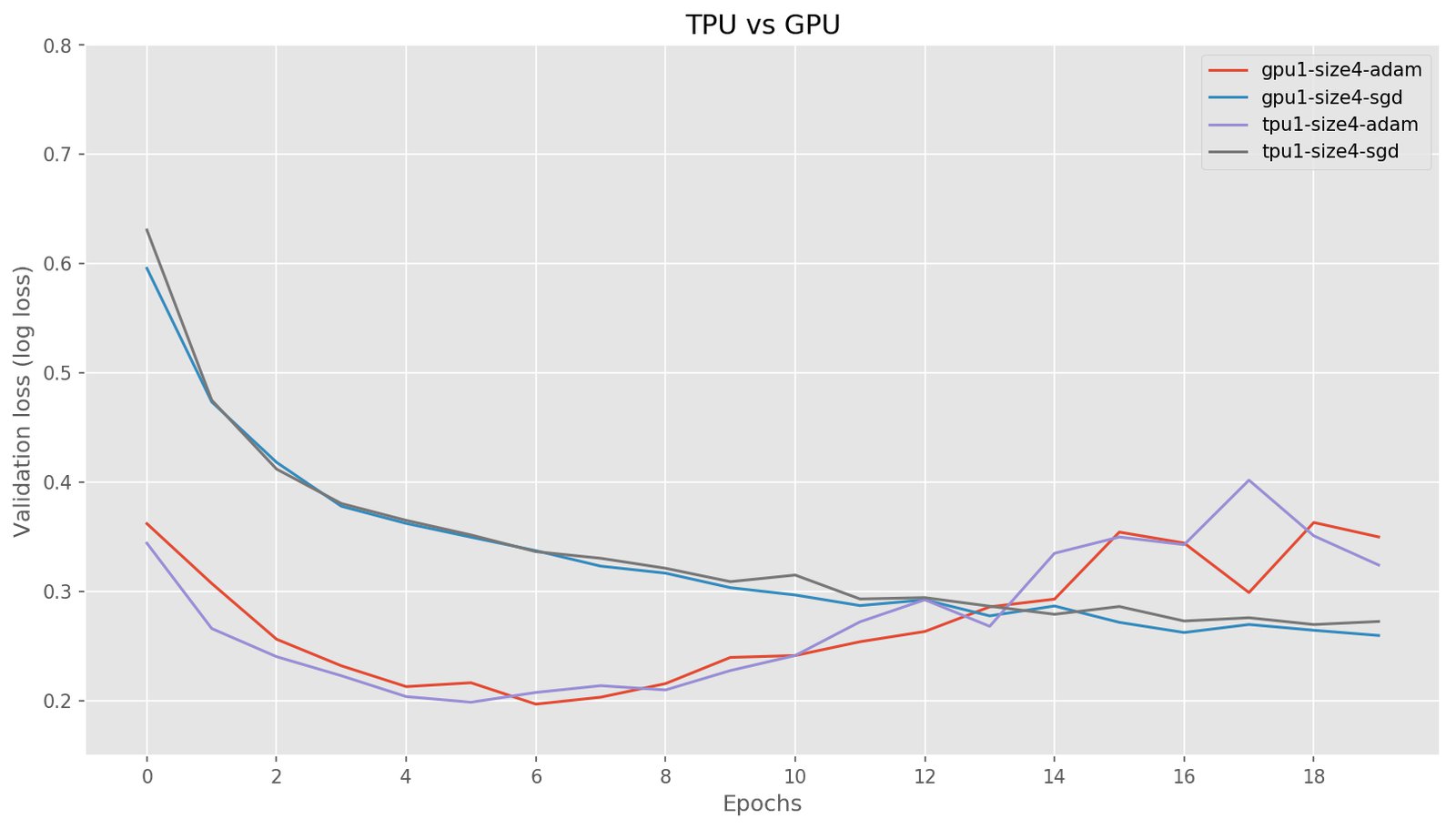
The SGD optimizer behaves similarly for 8 TPUs as for 8 GPUs, as would be expected. Initially, the Adam optimizer behaved much worse in our TPU experiments because we were using Keras’ Adam optimizer instead of TensorFlow’s tf.train.Adam. After changing our code to use the tf.train.Adam optimizer, Adam performed the same as in GPUs, albeit a bit slower. We also show the results for non-distributed learning for a single TPU core and a single GPU to indicate learning is similar:
Cost comparison
We’ve made a cost comparison to show the cost per training for all five tested devices. The running time of a network is an average of 5 runs, all trained with Adam until a 0.25 validation loss was reached. We show both the figures for regular machines and preemptible machines.
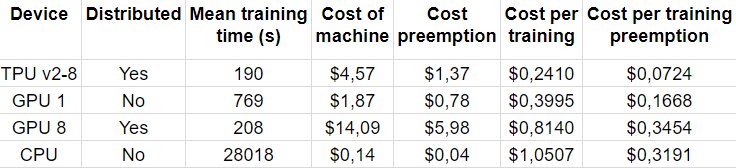
We can see that TPUs are most cost-efficient for this network. We should note that for larger networks these comparisons could differ a lot. For example, both the 8 GPUs and TPUs will see a speedup compared to non-distributed training.
Conclusion
TPUs are fast and cost-efficient, as tested in our smaller example networks. For these smaller networks and datasets we can see that the overhead of parallelization is high, but this is no different from using multiple GPUs.