Conflict-Free Pull Requests using dbt Core Custom Schemas

Sebas Higler

Using dbt Core over dbt Cloud can offer flexibility in use and understanding because of its open-source nature. However, some convenient (and proprietary) features offered by the dbt Cloud platform are missing. One such feature is the automated way by which each Pull Request (PR) runs dbt on modified models. It ensures they do not conflict with other PRs' changes running against the same database. Dbt Cloud solves this issue by creating a custom schema per PR in which all selected dbt models are created. This blog post will go over steps on how to achieve similar behavior using dbt Core.

The context
We will be using the following example dbt model lineage throughout:
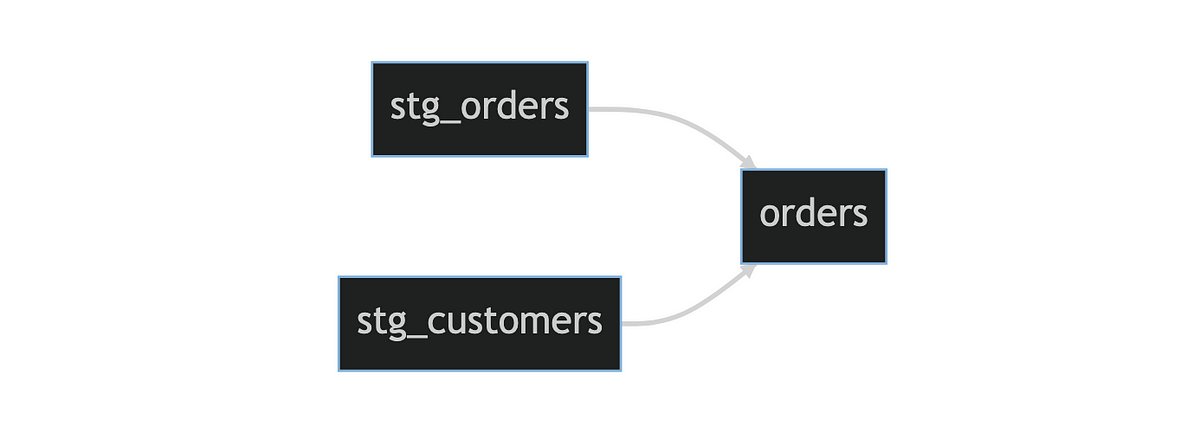
Lineage graph of dbt models used
Now, let’s say, we’ve made a change to stg_orders and pushed these to the git branch named feat/modify-stg-orders. We have also created a PR to merge this change into our develop branch. The develop branch, as the name suggests, represents the develop state of our dbt project where all new/updated features are initially merged into.
We have set up automated CI runs for PRs that run dbt on modified models and their downstream models to check the changes are valid. The associated dbt flags to achieve this are: --state /path/to/develop/state --select state:modified+ . We have a separate preceding step in CI that checkouts the develop branch, compiles it and returns the created target directory’s path which we pass to --state.
The following diagram shows the state of our database, reflecting the develop branch, in dark-gray and highlighted in orange are the additional elements, pertaining to our PR, that we wish to be created.
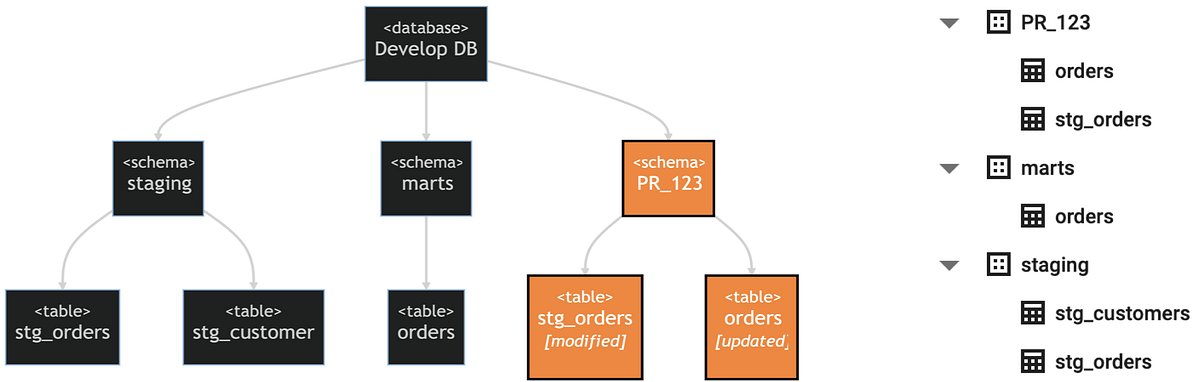
The database layout used shown as a diagram (left) and an example database view (right)
Providing the custom schema name
To provide the custom schema name to dbt we use an environment variable, let’s call it dbt_custom_schema , and use the env_var() macro to read it. To use the value provided by this environment variable we need to override the built-in macro generate_schema_name() such that we use the environment variable’s value, if given, to set the schema name. This looks as follows:
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- set env_custom_schema_name = env_var("dbt_custom_schema", "") | trim -%}
{%- if env_custom_schema_name != "" -%}
{{ env_custom_schema_name }}
{%- elif custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}
With the macro modified this way, it will use the dbt_custom_schema environment variable’s value as the schema name for all models whenever it is provided, regardless of model selection criteria given to dbt. This is an issue as we only want to assign the env_custom_schema_name to the selected models. Specifically, in our example that means we do not want stg_customers to be assigned the env_custom_schema_name, because it is not part of the selection criteria (as described in the previous section).
Using defer
To address this issue we use dbt’s defer feature. The --defer flag is used together with the --state /path/to/state flag, because defer will defer to the state file. This means that dbt will use a model’s configuration as described in the pointed to state file (rather than the current state file) whenever that model meets the following criteria:
- The model is not included in the model selection criteria of the current run
- The model does not exist as a database object in the current environment
Note that in our case the current environment uses env_custom_schema_name as the database schema name.
Our selection criteria selects all modified models and their downstream dependencies, so for all other models referenced in the selected models dbt will defer to the provided state file. In our case that means that stg_customers , which is not part of the selection criteria but is referenced by orders (which is part of the selection criteria), will defer to the provided state file for its configuration. Most important thing here is that this deferred configuration contains the default schema names, so it points to the already existing table in the database (the light-gray part of the database diagram shown above).
Note that the second criterion, the model not existing in the provided schema, is redundant in our case. The custom schema we provide won’t exist yet in the database and therefore by definition won’t contain any tables. We can choose to ignore this criterion by additionally providing the --favor-state flag alongside --defer.
Auxiliary implementation details
Here are several additional details that are important to mention:
- If by default models are assigned to several different schemas putting them in a single schema per PR might result in table name conflicts. This can happen when two or more models that by default are assigned to different schemas share the same model name. Generating custom model aliases could be a way to solve this edge case.
- It is important to regularly run
dbt runon thedevelopbranch to update models in the default schemas so they do not become stale. There might be models that are rarely modified or upstream from modified models and therefore won’t be included PR runs. These models being stale can subsequently have a negative or unexpected impact on the dbt run or tests. - Ideally the schemas created per PR are automatically cleaned up after the PR has been closed. To do this we can create a script or dbt macro that removes the PR-specific schema, including all its tables, from the database. Preferably this command is triggered to run on the PR close event, GitHub Actions for instance supports this.
Conclusion
In conclusion, creating a custom schema per PR to store all relevant models can improve a developer team’s workflow, making it less prone to conflicts and more organized. What makes implementing this feature in dbt Core possible is the combination of using an environment variable, overriding the generate_schema_name() macro, and using the (somewhat obscure) defer feature.