
Building a data platform: gotchas and best practices
Over the course of many different projects, we have built data platforms on every major cloud provider. While doing that, we learned about often overlooked issues and gotchas. Along the way we distilled some best practices. We want to share a condensed version of these insights with you by looking at a typical project.
By you, we mean you as a data platform and/or cloud infrastructure engineer, because many practices apply to every cloud infrastructure project out there. Sure, some of these practices are obvious, but then we ask ourselves why not everyone is doing this already.
In this post, we will focus on the following topics:
- Keeping an overview of resources and their costs.
- Staying in control of IAM policies.
- Managing your data.
Situation
You’re asked to build a data platform using one of the major cloud providers. It is requested that the platform supports:
- Data exploration via notebooks
- BI dashboarding via external BI tools such as PowerBI, Tableau, etc.
- Model training, batch transformation and live inference
- Multiple teams developing their models on the platform managed by you. They are allowed to deploy their own model related resources (e.g. training jobs) within the boundaries that you set.
After some initial design sessions you put on your cowboy hat and start building those components to prove your value to the organization. In no-time, the first notebooks are running, BI dashboards have been built and maybe even models have been trained.
As the platform grows, managing all aspects of the cloud becomes more complex. Let’s dive into three focus topics for this challenge.
Keeping an overview of resources and costs
Understanding what is happening in your platform starts with understanding what is running. Once you have the overview, you can optimize for e.g. costs, security, and user experience.
Luckily, even before getting any kind of overview, there’s one measure that always helps: budget alerts. It’s a bit trivial, but cannot be left unmentioned. Without knowing anything about the whole setup, this measure already prevents a bill from becoming too high.
A cloud environment doesn’t even have to be that big to lose track of why certain costs are generated. A public cloud is optimally used when resources are only there when they’re needed. In other words: when using ephemeral resources. Unfortunately, it’s exactly this kind of resource that makes traceability of costs hard.
As an example: you have many — lightweight — serverless compute functions running in your cloud environment. One of them is invoked at 02:00 and triggers a model training job. When you open your billing dashboard, you’ll notice significant costs for compute. The only active resources at that moment are those cloud functions. If you’ve set up the environment yourself, you know one of them sets up some ephemeral compute resources at night. When you’re new to the cloud environment, this conclusion is much harder to draw. Luckily, major cloud providers provide a good solution: setting up tags (or ‘labels’). These allow a more granular insight into your cloud billing.
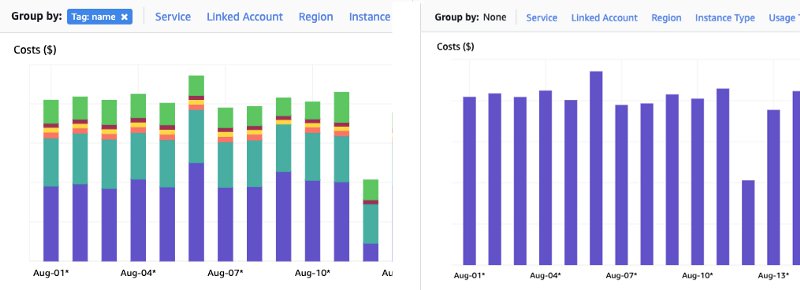
Left: overview with cost details per job. Right: default view that doesn't provide any per-job cost data.
In other cases, resources are created without you knowing. Mostly when setting up managed services, cloud providers configure them to save you the hassle. One way to be sure it doesn’t set up any unwanted resources, is to set up SEM alerts. Of course, this is only a side benefit of implementing SEM alerts, which most importantly improves platform security and should be a requirement anyway.
Actions
- Set up budget alerts and prevent bills becoming too high (GCP, AWS, Azure)
- Add tags/labels to every resource, to ensure that every line on your bill is explainable (GCP, AWS, Azure)
- Configure SEM alerts to limit the number of different resource types in your environment (GCP, AWS, Azure)
- Ensure that all cloud provider API calls can be viewed and queried with ease. By doing so, it becomes easy to find the origin of every SEM alert. Besides that, it will help you in debugging access denied responses which you will encounter at some point (AWS).
Staying in control of IAM policies
As your environment grows, expectations of your users grow. They now want to set up their own cloud resources with — for instance — Terraform. With an increase in resources and users, complexity of the set up grows, too. In this respect, there are two issues we’re highlighting: keeping an overview of all relations between resources, and validating whether the deployed resources are in line with your policies.
Getting an overview of policies
One question your legal department is likely to ask is: “Can user X access data Y?” This can be as simple as a single lookup in your IAM policies, but often proves to be more complex. Imagine this same user X logs on to a managed JupyterLab instance and that instance is running a different role authorized to query data Y. This means the same user can still query the data in question.
To make it easier to answer such questions, we’ve developed tools such as MIA (AWS) and gcp-iam-viz (GCP) to visualize IAM relationships between resources. They collect data about a cloud environment and store it to enable the visualization power of Neo4j.
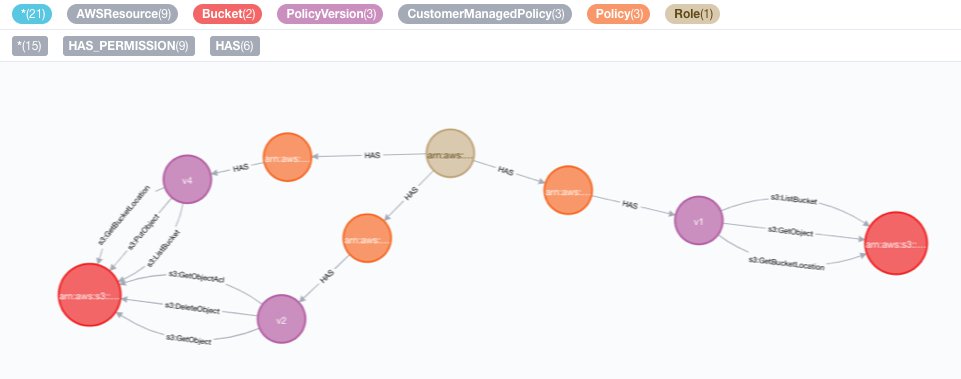
The "datascience" role has a policy that provides redundant permissions
Validating resource deployment
For legal purposes, most companies want to ensure their data is physically stored in specific regions. Another common policy often mentioned is a restriction on allowed services. Both are relatively simple policies most cloud providers support on an organizational level (AWS, GCP, Azure). There are use cases that are harder to cover, such as:
- Tags (or ‘labels’) must be applied to all deployed resources.
- Verify all used container images are from a trusted registry.
- Deployments by users cannot set IAM policies that affect personal accounts.
For these use cases, Open Policy Agent (OPA) fits perfectly. The Terraform plan (in JSON format) serves as an input to the programmed policy and can, as such, be validated. This check against the OPA policies must be enforced in a CI/CD pipeline.
Actions
- Configure all IAM policies using the least privilege principle. Yes, you and some of your users will be annoyed by this approach at some point. However, you will thank yourself many more times. We have the same love-hate relationship with writing tests.
- Create a design diagram of your IAM policies
- Use a tool to visualize and query IAM relations between resources, such as MIA (AWS) and gcp-iam-viz (GCP)
- Set up deployment validations with Open Policy Agent
- Set up basic permission boundaries (AWS) / Credential Access Boundaries (GCP).
Data management
By now, most organizations who are serious about data are familiar with setting up ELT/ETL pipelines of some sort. If you’re lucky, many of these load flows are even managed by the likes of Fivetran, Airbyte and Singer. Looking further downstream though, things tend to get fuzzier: users are making their own custom transformations over and over again. Tables aren’t partitioned according to the way they will be queried (e.g. time instead of event type). Or even worse: columns are being used in different ways than intended (e.g. multiple timestamp columns available of which it is unclear what they represent).
Besides challenges on the consumption side, there’s the topic of scaling data platform teams. In our experience, most greenfield data platform engineering projects start with every team member being a data platform engineer, ELT/ETL engineer and data steward all at once. When the team needs to grow, it’s easier to focus at scaling the technical roles because that results in measurable progress such as more datasets becoming available. However, this will create fertile ground for the downstream fuzziness described above: the focus was only on delivering feature requests without having a deeper understanding of these features.
Both the downstream use and scaling topics are organizational challenges in the end. As structuring teams is one of the hardest challenges out there, we advise two things: read up on different team structures and make sure that your data platform will always be a collaborative effort. That could mean going all-in on a data mesh or taking a more lightweight approach using tools such as DBT and scaling your data efforts using the analytics engineer role.
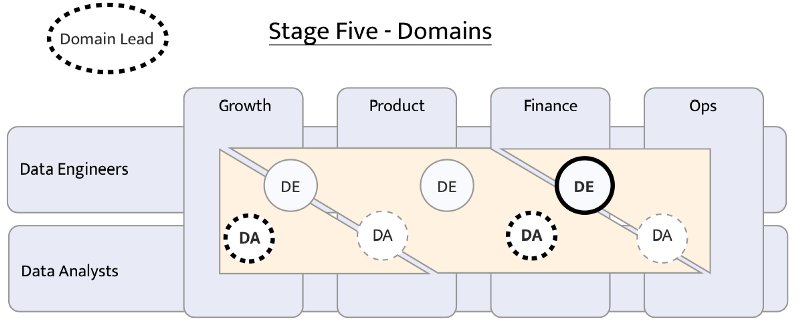
Example of an organisational structure implemented at Snaptravel. Their “domain structure” comprises one team where every domain is managed by a “domain lead”. The original article can be read here.
A technical enabler for a collaborative data platform is investing in a proper data catalog. In our opinion, the ideal catalog is a company internal public place where all datasets are documented, maintainers are visible, data lineage is provided, connection instructions are available for multiple tools, usage statistics and purposes are visible and data set work backlogs (e.g. bugs, feature requests) are shown. Every major cloud provider offers their own interpretation of a data catalog of which none of them offers all these features. Other catalogs we think are worth looking into would be Unity, TreeSchema, built-in DBT catalog or Alation.
The last topic we want to highlight is that of platform usage monitoring. In some ways, it’s ironic that we have yet to come across organizations building data platforms that are data driven. Being data driven in this context means knowing who is using your data platform in which ways such that you can act accordingly. That may be optimizing for user experience, secure access, costs and so on. In terms of technical approaches that work on every cloud provider, you could think of analyzing storage access logs. You will be surprised how often partitioning columns are not being leveraged. Another technical approach would be analyzing queries run against a compute engine such as BigQuery or Athena. By doing this, you can determine table popularity and lift very common computations higher upstream to serve data platform users better. In the end though, this is where we’re back at the technical solutions for an organizational challenge. Making sure that domain experts are in charge of data sets and that domain experts talk to data set users to discover and improve how their data is being used.
Actions
- Have a domain expert in charge of every data set. Call it a data steward, data product owner, analytical engineer or anything you like.
- Regularly assess the structure of your data related teams. The DBT website contains some very thoughtful insights into different structures.
- Ensure compatibility with company BI tooling from the start. This is the interface you will use to create showcases to your sponsors.
- Use a data catalog. This should be the first interface to your users, and the second most important one to your sponsors.
- Use a data schema and transformation management tool that both engineers and analysts can use. At the time of writing, we think DBT is the best candidate. It is one of the key tools that will enable a collaborative data platform.
- Embrace data access control tooling from the start. If you’re building a successful platform, a need for access controls will emerge at some point. Prepare for table level, column level or even row level access control requests. If you don’t have (access control features in) a data warehouse, you can always use storage level access up to the partition level.
- Monitor table usages through at least storage access logs. Ideally, analyze queries being run to understand how users are querying data sets. That will help you find optimizations such as partitioning strategies or creating new precomputed tables to prevent redundant querying.
- Provide insight into the querying cost model. Many users probably aren’t aware of the cost of their queries. Most likely, your users are willing to be smart about this when they know how it works.
If you have any actions to add, or if you want to discuss our findings in more detail, please reach out!