Kinesis Data Analytics SQL: a cautionary review
Considerations for stateful real-time feature processing
You use AWS. You need to perform real-time feature processing all while maintaining state. Could Amazon Kinesis Data Analytics be a solution to your problem? What about concerns such as testability, code reusability, and its fit in your data science landscape? In this post, I will address these questions at the hand of the problems I found with Kinesis Data Analytics SQL.
Real-time features
When it comes to real-time analytics, Amazon Kinesis Data Analytics comes highly recommended. Kinesis Data Analytics’ integration with Kinesis Data Streams and its serverless model makes it an ideal choice in an AWS system. While working on an AWS recommendation system, I needed to calculate features in real-time. These features required state (i.e. historical data) to be calculated. Once calculated, the features acted as input to machine learning models for predictions and subsequent recommendations.
The features use distributed user interactions, for example, click-through-rates (CTRs), views, and purchases. Event data enters a Kinesis Data Stream, gets processed and then flows into another Kinesis Data Stream, as illustrated below. The feature processing component is the topic of discussion and where Kinesis Data Analytics fits in.

Component layout for real-time feature calculations.
In my situation, I required features based on 1 day and 7 days’ history (i.e. stateful processing). Furthermore, the landscape in which this subsystem would operate is one with mostly Python and SQL. Hence the constraint to use a SQL Kinesis Data Analytics application instead of a Java + Apache Flink application.
I evaluated Kinesis Data Analytics SQL on three aspects: testability, suitability, and code reusability.
Testability
Delivering quality software starts with testing. The feature processor needs to calculate features correctly so that both it and other components function as they should. Verifying this correct functioning implies at least some form of unit and integration testing.
Unit testing for Kinesis Data Analytics is complicated because it is a managed (serverless) service. Furthermore, AWS added streaming SQL functionality to the SQL:2008 standard, which means standard SQL tooling would not run the code. There is at least one tool, LocalStack, that claims to run Kinesis Data Analytics SQL applications. Using LocalStack would, however, require at least the (paid for) Pro Edition. Then there is also the question of why mock the AWS cloud instead of following the integration testing solution stated next.
On the integration testing level, testing can be performed with Terraform or another Infrastructure as Code (IaC) tool. The IaC tool would create the input and output Kinesis Data Streams along with the Data Analytics application. Once deployed, Boto3 can be used to send test input to and read output from the respective Data Streams. This setup is, however, far from ideal because there are three components and the IaC code that need to work together just to test the application.
Clearly testing a Kinesis Data Analytics SQL application is not easy. It requires either commercial tooling to execute the custom SQL syntax or unit testing has to be left out. This complexity undermines test-driven development. I did, however, take an optimistic view and allocated a 50% pass for this criterion.
Suitability
For suitability, I looked at how Kinesis Data Analytics fits into the overall landscape and how well it can solve the stateful real-time feature processing problem.
The data science landscape I worked in was dominated by Python and SQL. I enquired if the Java + Apache Flink application would be an option but SQL was the preferred option.
Using SQL, I developed a proof of concept application to determine if Kinesis Data Analytics was suited to stateful real-time feature processing. The short answer is no. The explanation stems from two inter-related problems. Firstly, the reingestion of historical data and secondly, the monotonicity of event times.
The reingestion of historical data is only possible if the event time of the data is used in calculations. If the processing time were used, loading historical data would get mangled with real-time data causing incorrect calculations. For example, consider the need for a 7-day average CTR and a 1-day CTR. When reingesting data of 5 days ago, this data would influence the 1-day average CTR if calculated on processing time. Calculating these CTRs using the event time would correctly use the reingested 5th day’s data for the 7-day average CTR and not the 1-day average CTR.
Fortunately, Kinesis Data Analytics SQL supports calculations on event time. All that’s needed is for the event times to be monotonically increasing or decreasing. This monotonicity is, however, a problem in distributed environments. Just consider the delay of event data being sent over the internet, as shown below. It could easily happen that an event (T1) occurs first but arrives after another event (T2) that occurred later.
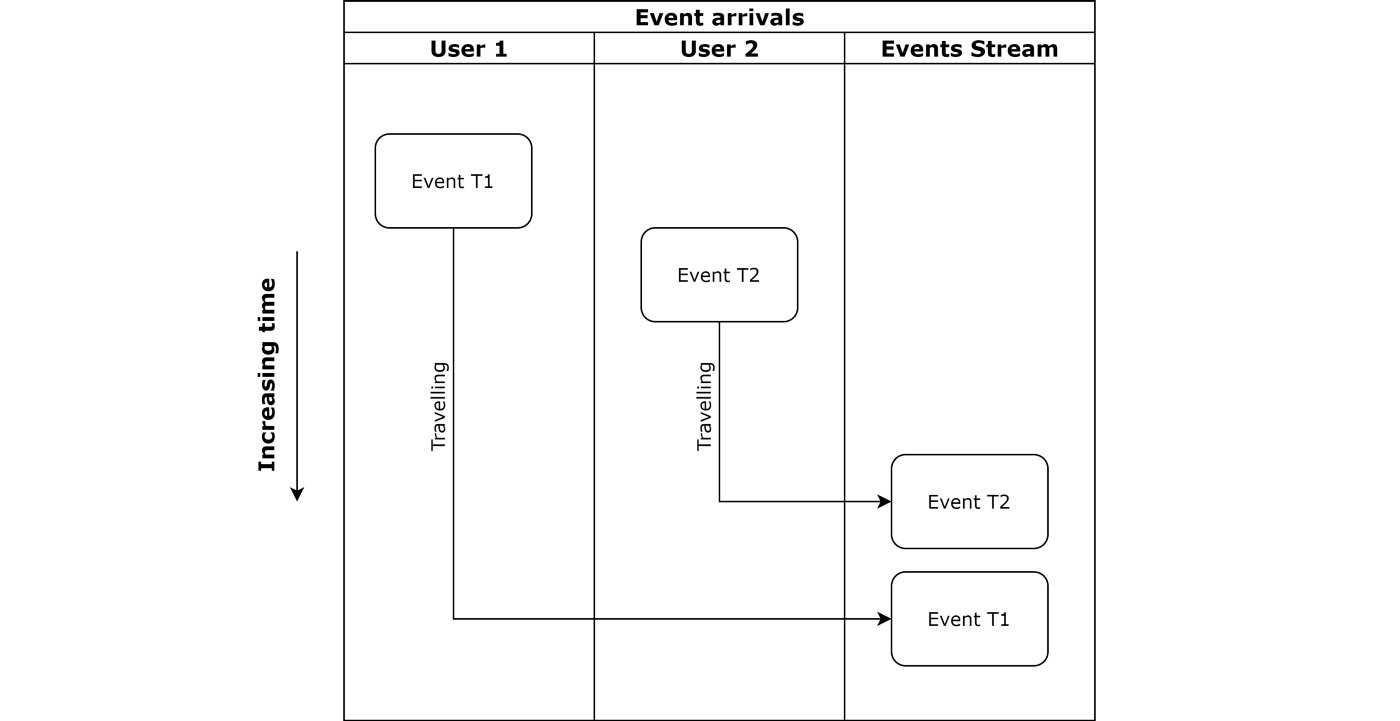
A sequence with a first-occurring event (T1) arriving after a second-occurring event (T2).
Ensuring monotonicity requires another application to order the events on their event time and only then placing them into the stream. This adds a delay in having the data available and increases complexity by adding another component to the system.
An argument can be made for adding more complexity and spending more time to ensure monotonicity but this is not ideal. In my situation, this additional complexity was unwanted. This is why Kinesis Data Analytics SQL receives a 50% pass since it is possible to do processing on event time but not without additional work.
Code reusability
In my case, there was an opportunity for code reuse. Reusing the real-time feature calculation code was possible in offline model training or exploration. Therefore, using similar code while avoiding more maintenance burdens, makes reusability a valid consideration.
In a sense, Kinesis Data Analytics SQL was set up to fail in code reusability from the start; it is an AWS managed service with a customised SQL language. No database system or software I know can use Kinesis Data Analytics’ SQL code. Something using, for example, Python (with pandas) would be more reusable.
There are also cloud provider lock-in considerations that impact code reusability. By using Kinesis Data Analytics SQL the calculation code would not be portable to another cloud provider. This could be a problem if a system needs to run in a multi-cloud setup.
For this final criterion, Kinesis Data Analytics SQL receives a fail.
Final tally
The tally for Kinesis Data Analytics SQL shows a failure. It achieved 50% in testability due to its testing difficulties. It also achieved 50% in suitability, due to its monotonic requirements and there is no code reusability. Therefore, Kinesis Data Analytics SQL was not the ideal solution for stateful real-time feature processing in a Python/SQL landscape. Still, it may be useful but only if you have none of the concerns mentioned here. Also, note that Kinesis Data Analytics Java + Apache Flink is still a viable solution but not in a Python/SQL data science landscape.
Despite Kinesis Data Analytics SQL not being the ideal solution, there are many AWS alternatives to consider. The alternatives I considered were AWS Lambda and AWS Fargate + Elastic Container Service. The final choice became Fargate as it satisfied all the requirements and it was more suited to stateful processing as opposed to AWS Lambda.
I hope this post helped you to make an informed decision about Kinesis Data Analytics SQL, especially for the stateful real-time feature processing. In general, I also urge you to think about the testability, suitability, and code reusability of a solution before starting on your path.