
Advantages of Serverless Services for Servitization Teams
Imagine: you are working for a company that produces tires. For many years now, your company has been collecting sensor data from the previously sold tires. Now the time has come to extract value from that data. You will lead the implementation of a data-driven predictive maintenance service, so your company can take over responsibility for timely maintenance from the customer (“servitization”). You need to gather the right expertise around you, and build a digital infrastructure. But how do you limit the amount of the digital/technical knowledge needed by the team, if digitalization is not your core business?
This blog summarizes why you may look for managed services that are serverless. The comparison between serverless and non-serverless options comparison can be made using the CNCF definition:
“Serverless refers to the idea that consumers of serverless computing no longer need to spend time and resources on server provisioning, maintenance, updates, scaling, and capacity planning.”

Download our free whitepaper to learn everything you need to know about the servitized business model, why it matters that you're not an IT company and the directions your business model could take. And remember, serverless is the IT embodiment of a mantra we should all be interested in: work smarter, not harder.
Download Whitepaper Achieving Servitization
Case 1: Storing data in a database
The team decides to store data in a database on AWS, and need to choose how to set up the database. Two extreme opposites are:
- self-managed database on Elastic Compute 2 (EC2)
- serverless with AWS Aurora
AWS Relational Database Service is somewhere in between these options.
The choice they make determines the work will have to keep the database running, and the corresponding capabilities. Table 1 compares the options using the CNCF definition of serverless.

Table 1: storing data, do I need to spend time on ...?
A number of time-consuming tasks are avoided here if serverless is chosen:
- Starting EC2 machines, networking, security groups, managing access to the servers, backups and installing the database
- Updating and upgrading the operating system and the database version
- Configuring up and downscaling of the resources to support fluctuations in required storage size and usage intensity
- Making estimates of the required storage and CPU to avoid over and under capacity
Serverless databases thus requires fewer actions and capabilities from the team. These actions and capabilities do not vanish, but become the responsibility of the cloud provider that offers the serverless service.
Case 2: Tire wear model code deployment
Once the data has been stored in the cloud, it must be prepared for use. The data is cleaned, transformed and stored again. Then analytical models analyze the data and provide advice on maintenance. To this extent, a domain specialist digitalizes a physical model that, for example, calculates wear on the tire. The question is, how will this model run in the cloud environment?
Three different approaches in which Python is for the tire wear model (visualized in Figure 1):
- Running code on virtual machines. In this approach, virtual machines are remotely triggered to run the tire wear model, for example over Secure Shell (SSH). As the business grows, larger virtual machines may be used (vertical scaling), but when this is not sufficient, multiple machines can be used. Distributing tasks over the different machines will imply using some framework or creating custom “hacks”.
- Serverless functions or Function as a Service (FaaS). This option requires uploading the model code and invoking the function. Serverless functions are (often) limited in their duration and memory. You invoke the function with different parameters, for example belonging to different tires. The FaaS framework will take care of spawning independent processes and the underlying resources instantly.
- Using containers in Kubernetes. This option will run the code in Docker containers, which are orchestrated by Kubernetes. The code is stored in Docker images, which are build by the developer. There are many ways to run the code on Kubernetes, for example with Jobs, or by installing a FaaS framework on top of Kubernetes (like OpenFaaS).
- (new: FaaS on AWS now runs Docker containers.)
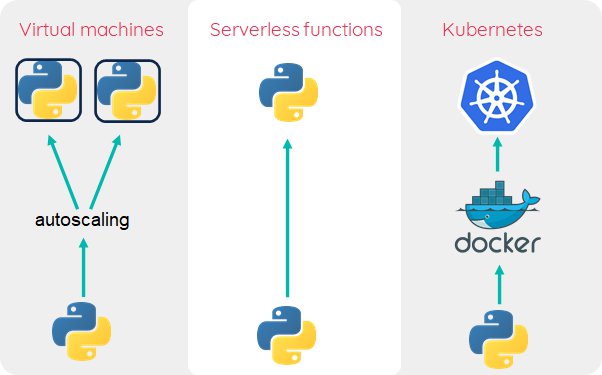
Figure 1: Three ways in which the physical model can be deployed in a scalable manner.
All three solutions will run the Python code in the cloud, but the approaches are very different. Each option implies different tasks and capabilities for the team (see Table 2 for evaluation using the CNCF definition):
- A virtual machine approach is accessible because it is similar to executing code on a local machine, but requires an expert to manage the virtual machine.
- Kubernetes reduces infrastructural tasks but requires knowledge of Docker and Kubernetes.
- The serverless approach requires knowledge of the serverless framework, but does not require management tasks.
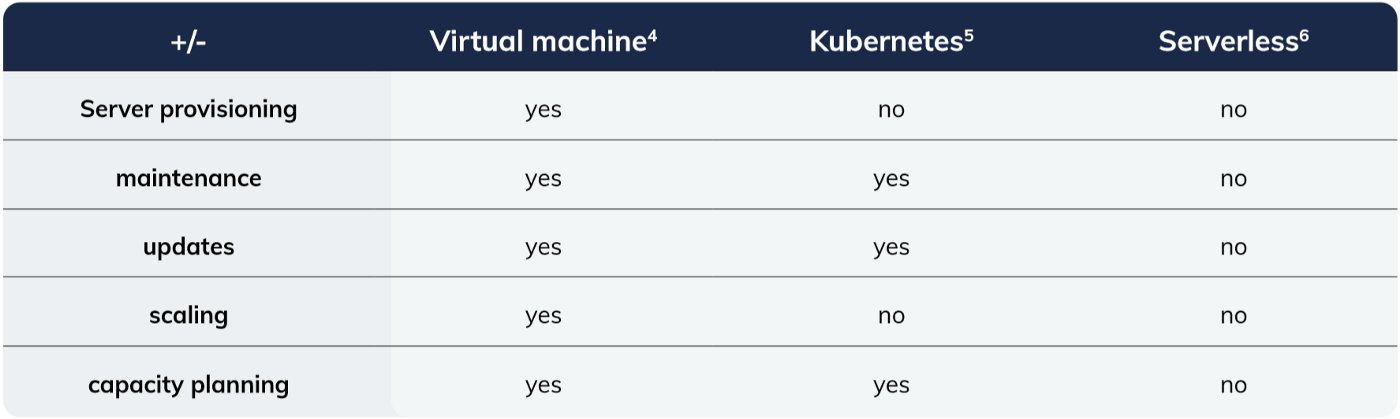
Table 2: Processing data: do I need to spend time on ...?
The serverless functions option has advantages comparable to the serverless database in Case 1:
- Starting EC2 machines, networking, security groups, managing access to the servers, backups and installing the tire wear model.
- Updating and upgrading the operating system
- Configuring up and downscaling of the size and number of virtual machines
- Estimating the CPU and memory requirements of the virtual machines
An advantage over the Kubernetes option is that the steep Kubernetes learning curve is avoided.
If you like to get started with serverless infrastructure, I shared some experiences in recent blogs:
Case 3: …?
Data storage (Case 1) and code deployment (Case 2) are just a few of the topics the team will encounter. When setting up a reverse proxy, or message queue, a similar assessment with the CNCF definition can be made. If the team happens to be on Kubernetes, a wide range of serverless tools that may be used. An overview is found on the CNCF serverless landscape.
Conclusion
If your team starts to develop a cloud application, it’s important to make conscious decisions on the responsibilities you take for the digital infrastructure and frameworks. Using virtual machines and building you own world is always an option, but moving responsibilities to the cloud vendor could be a better choice. Serverless moves many responsibilities to the cloud vendor.
As a case study, data storage and code deployment were assessed using the CNCF definition of serverless. From the definition we see that server provisioning, maintenance, updates, scaling and capacity planning become tasks of the cloud vendor when choosing a serverless services.
Footnotes:
- AWS Elastic Compute 2
- By setting capacity units
- -
- AWS Elastic Compute
- AWS Elastic Kubernetes Service with Fargate, Azure Kubernetes Service
- AWS Lambda
Advertorial
Are you considering a serverless approach for your servitization project?
Find out how serverless technologies minimize adaptation for industrial manufacturers by downloading the whitepaper. The document will be delivered to your inbox!

